
MobileUNETR:A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation
MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation
论文:《MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation》(ECCV 2024)
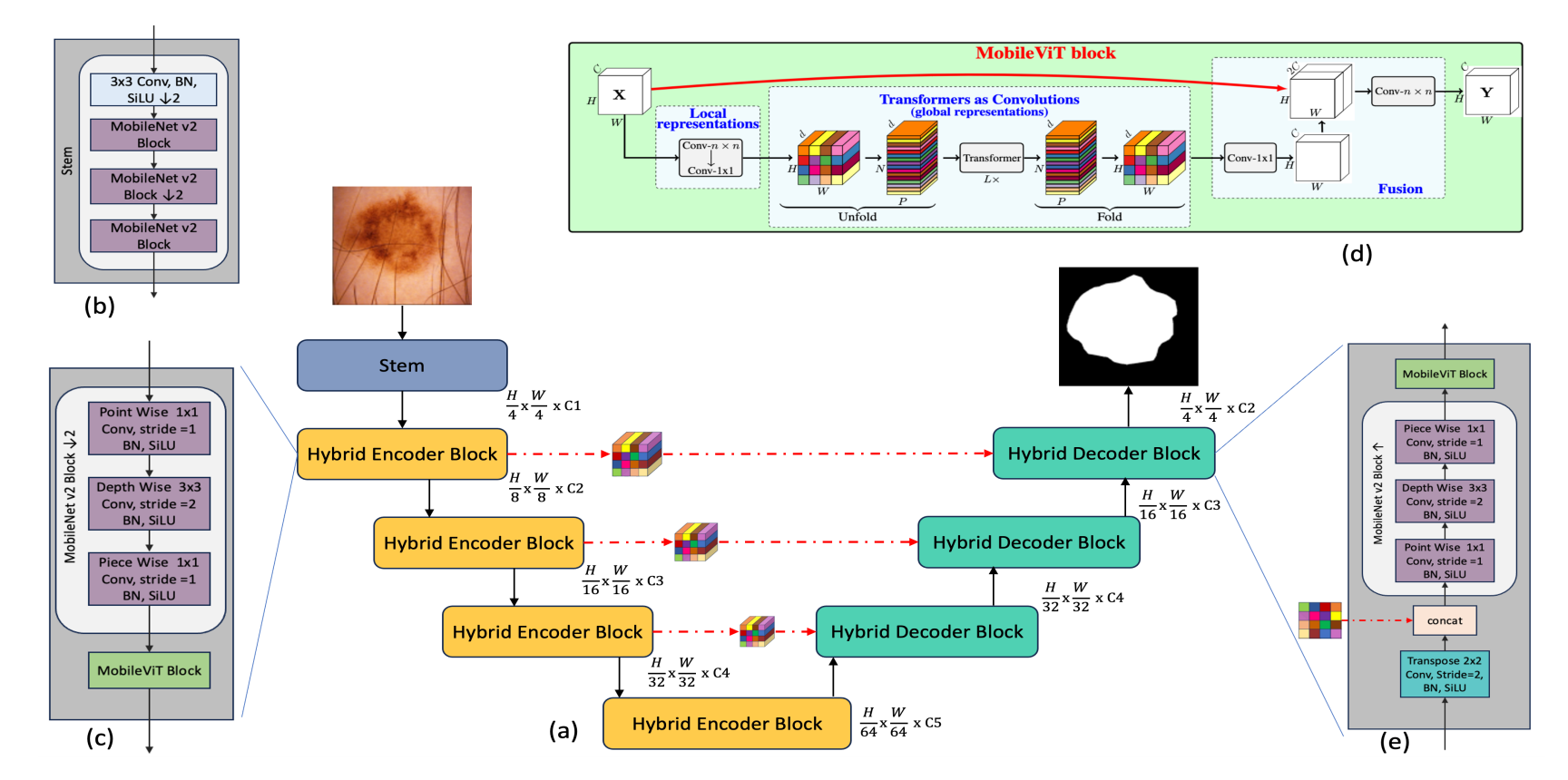
Hybrid Encoder Block:利用深度可分离卷积将特征投影到高维,再利用MobileViT block捕获局部和全局信息
Hybrid Decoder Block:首先,使用转置卷积进行上采样;然后,将得到的特征与跳跃连接的特征进行拼接;最后,使用MobileViT block得到改进后的分割结果
MobileViT block
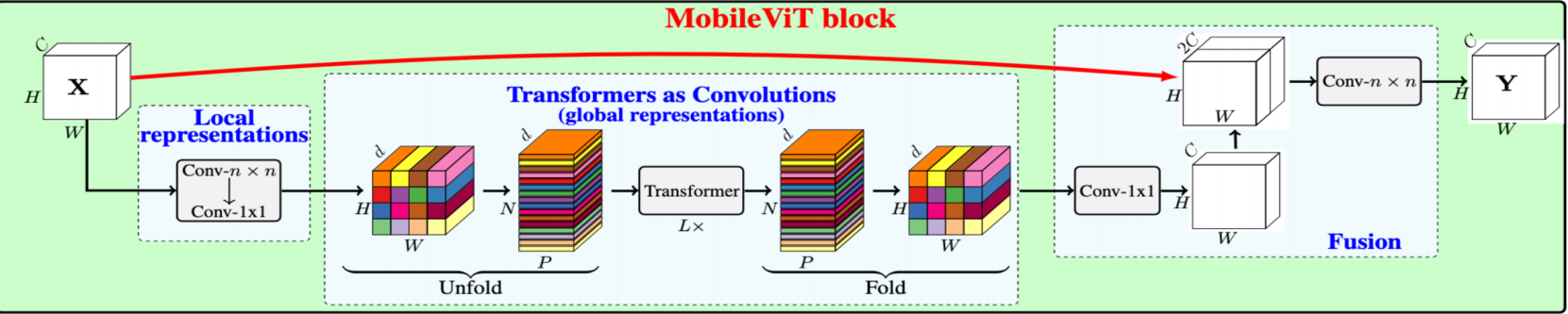
- Local representations:先使用n×n卷积进行特征提取,再使用1×1卷积调整通道数,获取局部特征
- global representations:通过Unfold和Fold操作实现,对相同颜色的小色块会进行Attention,以此来减小Attention计算的复杂度,来获取全局特征
- Fusion:通过与原始特征图的拼接,来实现融合
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 丹青两幻!
相关推荐



评论

