
3D UX-NET
3D UX-NET
论文:《3D UX-NET: A LARGE KERNEL VOLUMETRIC CONVNET MODERNIZING HIERARCHICAL TRANSFORMER
FOR MEDICAL IMAGE SEGMENTATION》(ICLR 2023)
1.网络结构
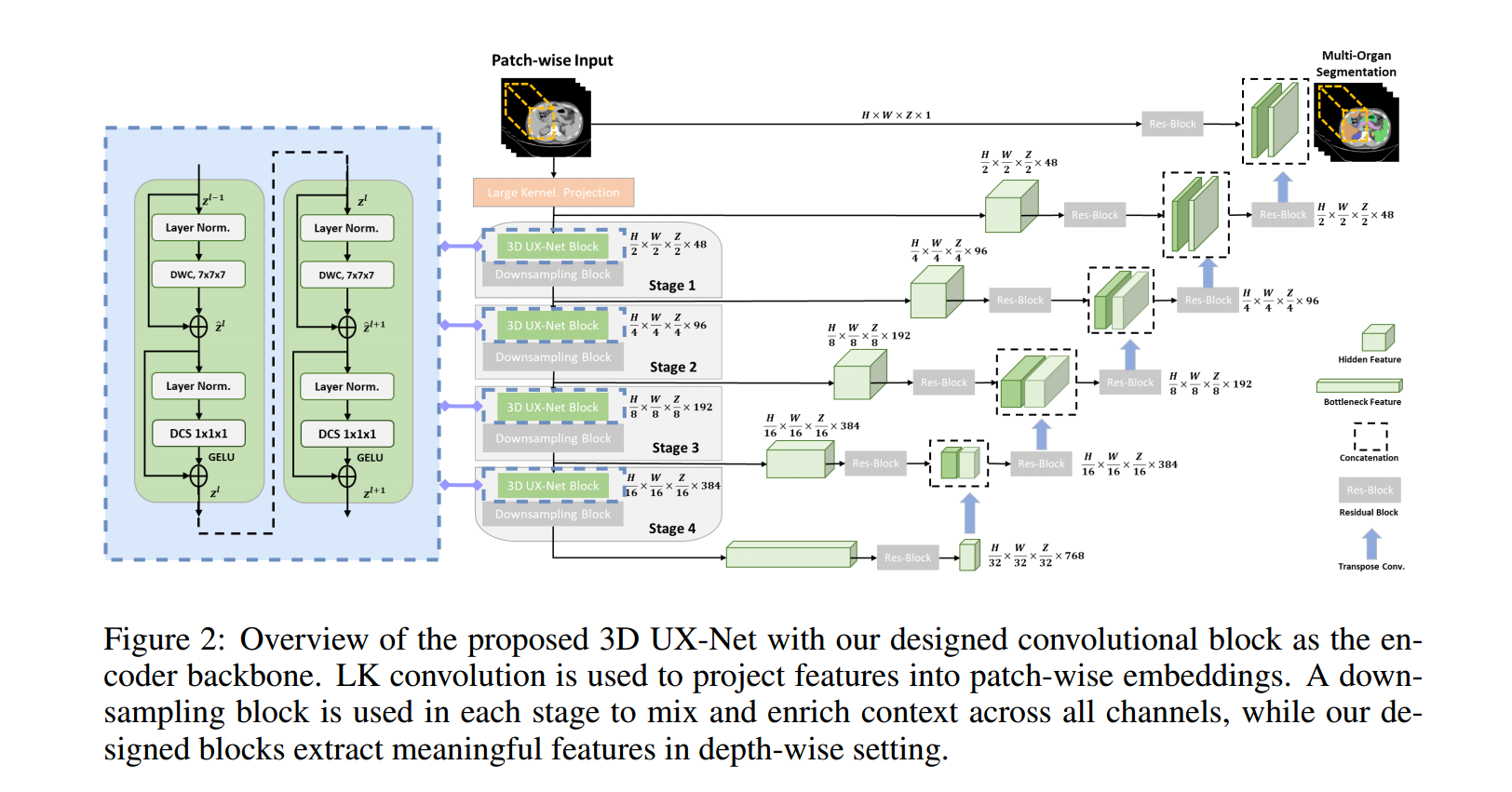
采用具备大卷积核的投影层来提取 patch-wise 特征作为编码器的输入
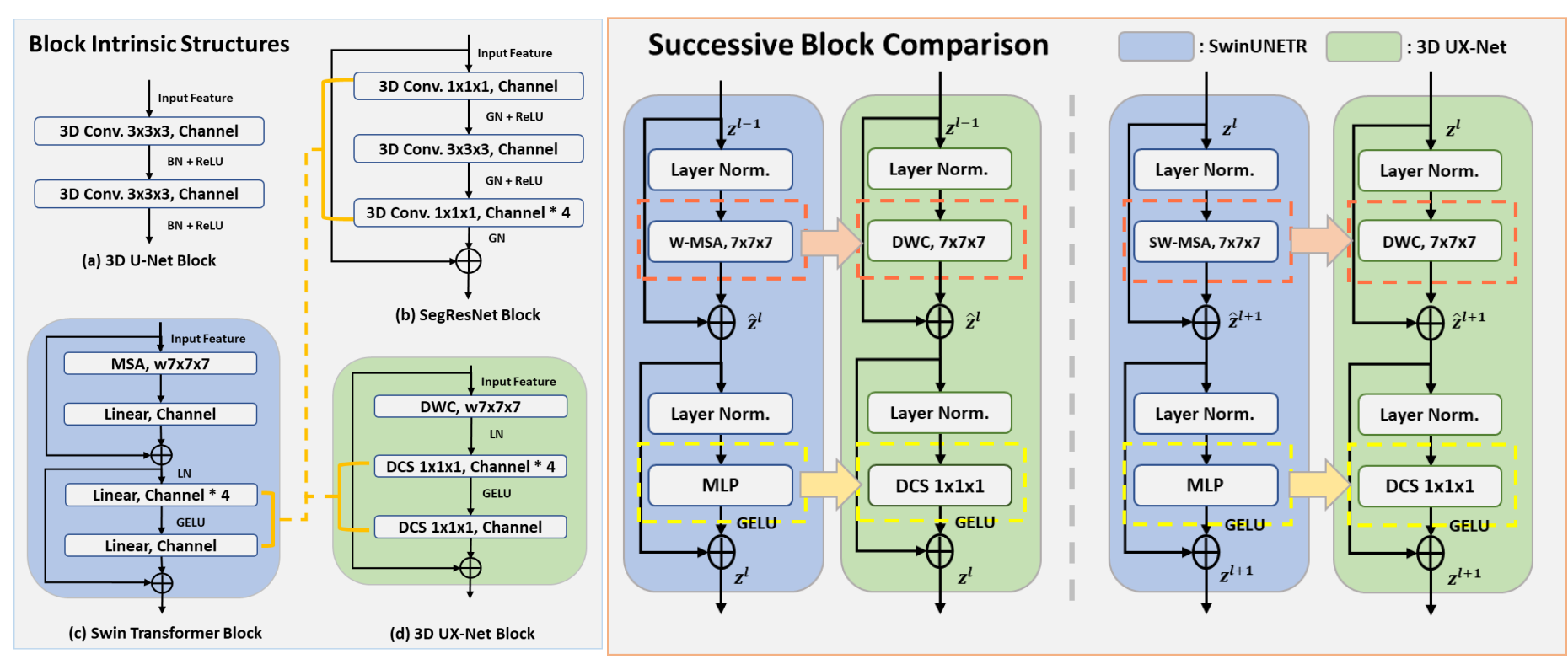
对Swin transformer的transformer block做了替换:
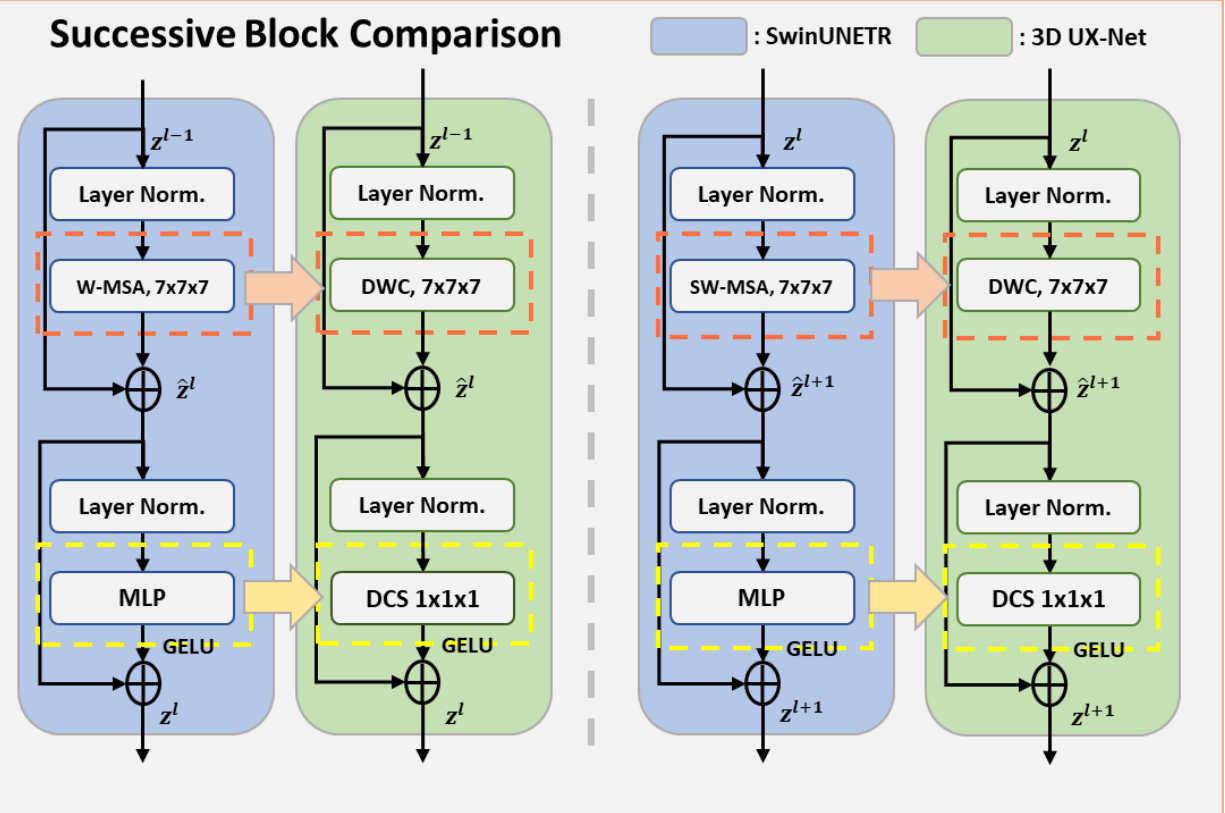
使用大卷积核(7 × 7 × 7)的深度卷积来模仿Swin Transformer的局部自注意力和窗口移动。
使用2 × 2 × 2、步幅为2的标准卷积块来实现下采样
在Swin Transformer中MLP隐藏层维度比输入维度宽四倍,引入了具有 1 × 1 × 1 卷积核大小的深度卷积缩放(DCS),以独立地线性缩放每个通道特征,减少跨通道上下文产生的冗余信息
DCS:1x1x1的深度卷积+1x1x1的分组卷积
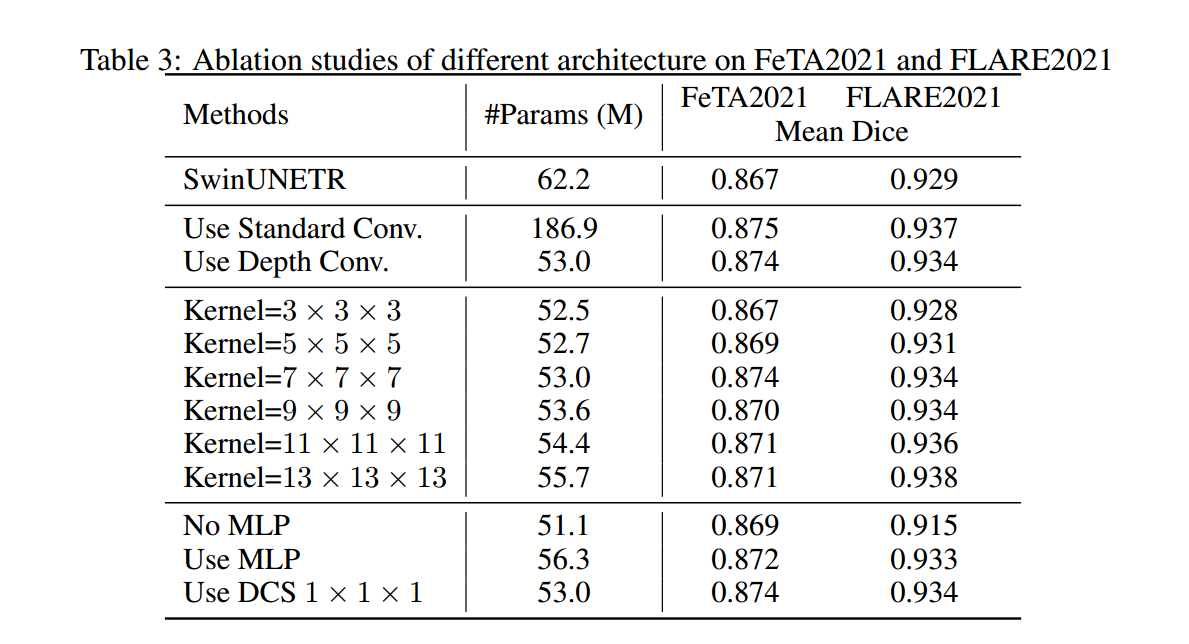
从实验中发现:使用深度卷积缩放(DCS)参数量得到了减小,效果并没有下降
编码器的输出特征由残差块作进一步的处理,以稳定提取的特征。(残差块由两个经过实例归一化的后归一化3 × 3 × 3卷积层组成)
转置卷积层实现上采样,其输出的特征与编码器的输出进行连接后,再次输入到残差块中。
2.实验结果
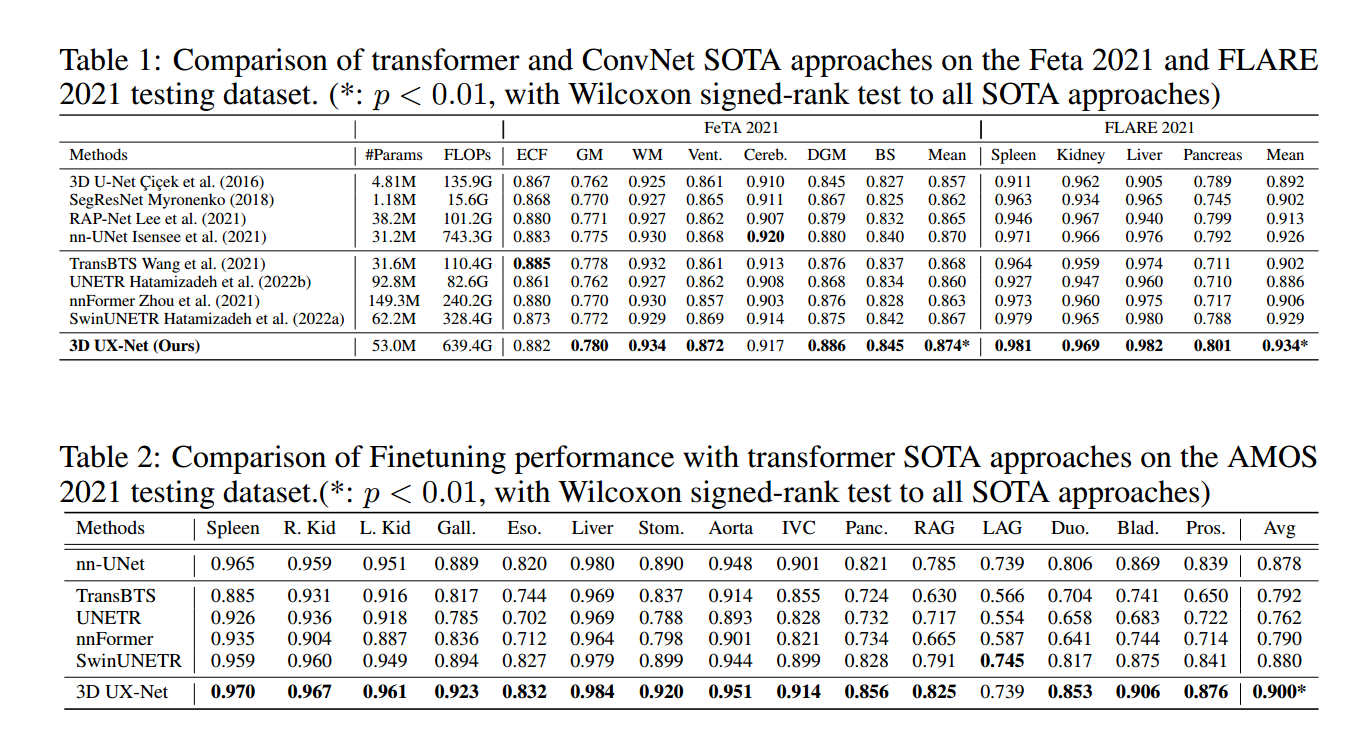
3D UX-Net 在这几个分割任务中均展示出最佳性能,并且 Dice 分数有了一定的提高
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 丹青两幻!
相关推荐



评论

