
Improving Transformers with Dynamically Composable Multi-Head Attention
Improving Transformers with Dynamically Composable Multi-Head Attention
论文:《Improving Transformers with Dynamically Composable Multi-Head Attention》(ICML 2024)
多头注意力(MHA)的不足:对于多头注意力(MHA),其注意力头是独立工作的,这种独立性限制了每个头能捕捉到的特征和关系的多样性,注意力矩阵存在低秩瓶颈和冗余。
作者提出了动态组合多头注意力(DCMHA),其解决了MHA的不足,通过动态组合注意力头来提高模型的表达能力。
动态可组合多头注意力(DCMHA)中,核心是一个 Compose 函数,它根据查询 和键 以及可训练参数 ,将它们的注意力向量 ∈A:ij∈RH 转换为新的向量
注:假设T、S是查询和键序列长度,用表示第h个头的注意力矩阵
表示注意力向量,它是查询向量 和键向量 之间的注意力得分向量
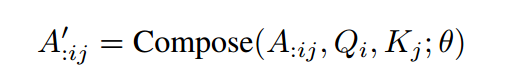
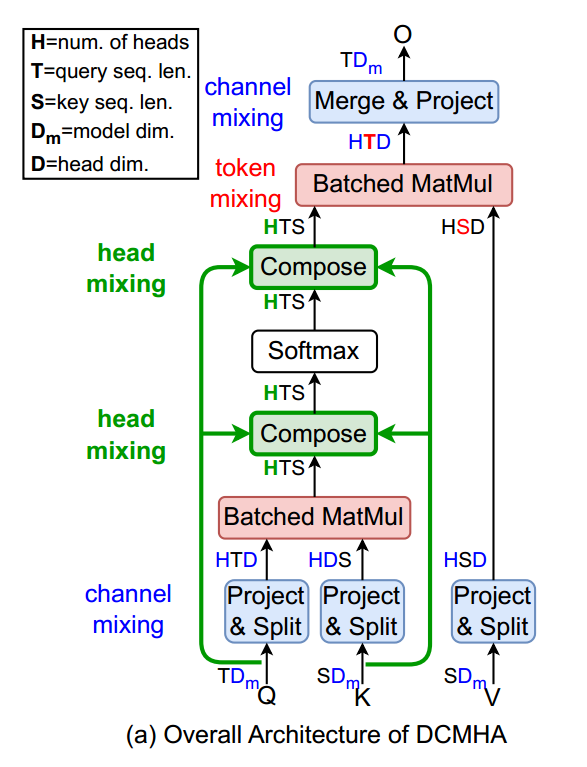
为了实现 DCMHA,在 MHA 的计算中插入两个 Compose 函数,其中一个在 softmax 之前应用于注意力分数张量 ,另一个在 softmax 之后应用于注意力权重张量 ,步骤如下:
- 注意力分数 计算:

- 注意力权重 计算:

DCMHA模块最后的输出为:

Compose 函数:
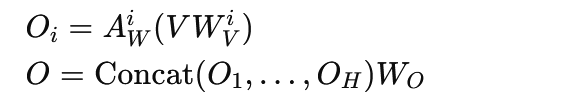
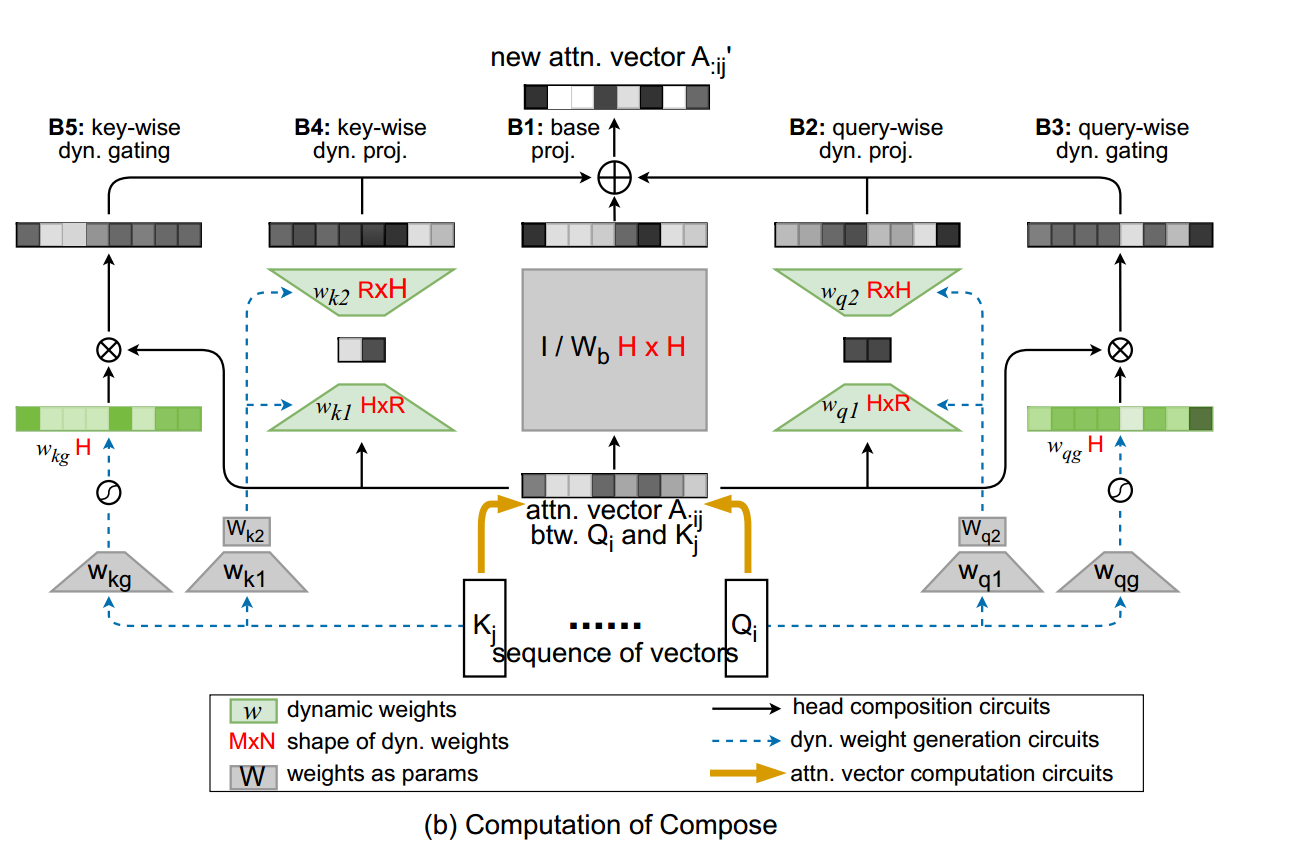
注意力向量经过5个分支进行变化,然后相加
第一个分支(基础投影):首先由一个权重矩阵进行投影
第二个分支(查询的动态投影):通过 投影到低维 ,再通过投影回原始维度,其中动态权重 和 由 查询向量 计算得出。
第三个分支(查询的动态门控):乘以一个门控权重控制每个头保留或忘记原始分数。
第四个分支(键的动态投影):类似于第二个分支
第五个分支(键的动态门控):类似于第三个分支
最终的 为:
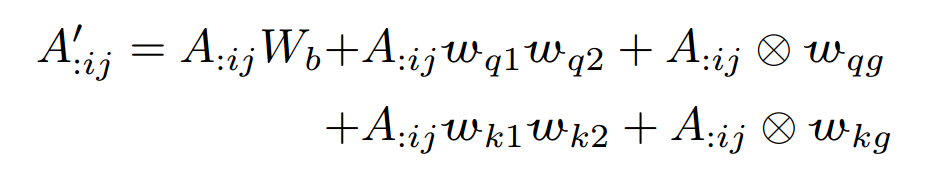
注:DCMHA的可训练参数为:{、、、、、、}




