
AGILEFORMER:SPATIALLY AGILE TRANSFORMER UNET FOR MEDICAL IMAGE SEGMENTATION
AGILEFORMER: SPATIALLY AGILE TRANSFORMER UNET FOR MEDICAL IMAGE SEGMENTATION
论文:《AGILEFORMER: SPATIALLY AGILE TRANSFORMER UNET FOR MEDICAL IMAGE SEGMENTATION》(arXiv 2024)
作者使用了一种新的patch embedding取代了vit-unet中标准的patch embedding
采用空间动态自注意力来捕获空间变化特征
提出了一种新的多尺度可变形位置编码
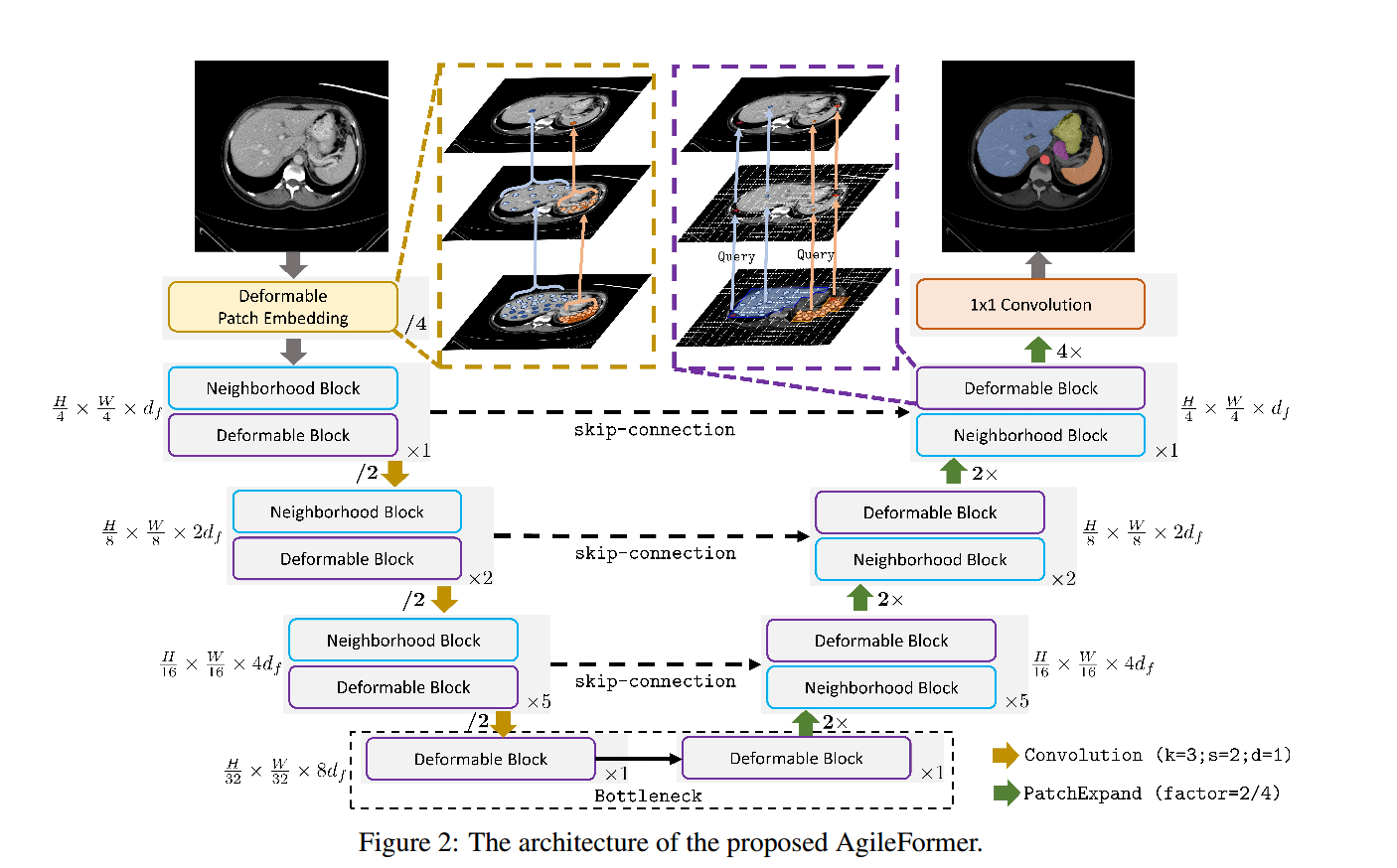
可变形的patch embedding
通过可变形卷积卷积核的采样位置可以根据输入的特征图进行微小的偏移,从而可以实现更灵活的特征提取。通过引入可变形的采样位置,使得补丁嵌入可以更好地适应不规则的结构,从而提高了特征提取的灵活性和准确性。
第一个patch embedding:使用两个连续的可变形卷积层,这两个连续重叠的可变形patch embedding可以更好地提取局部特征,弥补了自注意力中局部性的不足
下采样层:通过3×3卷积完成下采样
空间动态自注意力
可变形多头自注意力:
第h个头的计算过程如下:
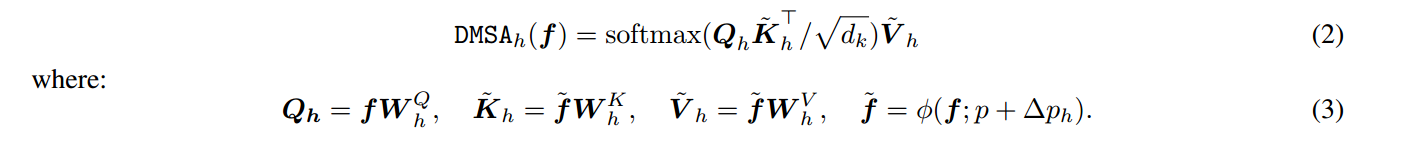
注:f是输入的特征图,ϕ是插值函数,用于生成偏移后的特征图,是第h个头部生成的偏移量,其通过一个卷积层生成
邻域多头自注意力:
与标准自注意力不同,标准自注意力计算特征图f中每个位置p的元素与其他位置元素的相似度,而邻域注意力只利用位置p周围k个最近邻的信息来计算注意力权重,而不是与所有位置的元素计算相似度。减少了标准自注意力的计算复杂度,从二次降至近似于空间维度线性的复杂度。重新引入了局部操作到自注意力中,使得模型具有平移等变性,从而提高了保留局部信息的能力。
多尺度可变形位置编码
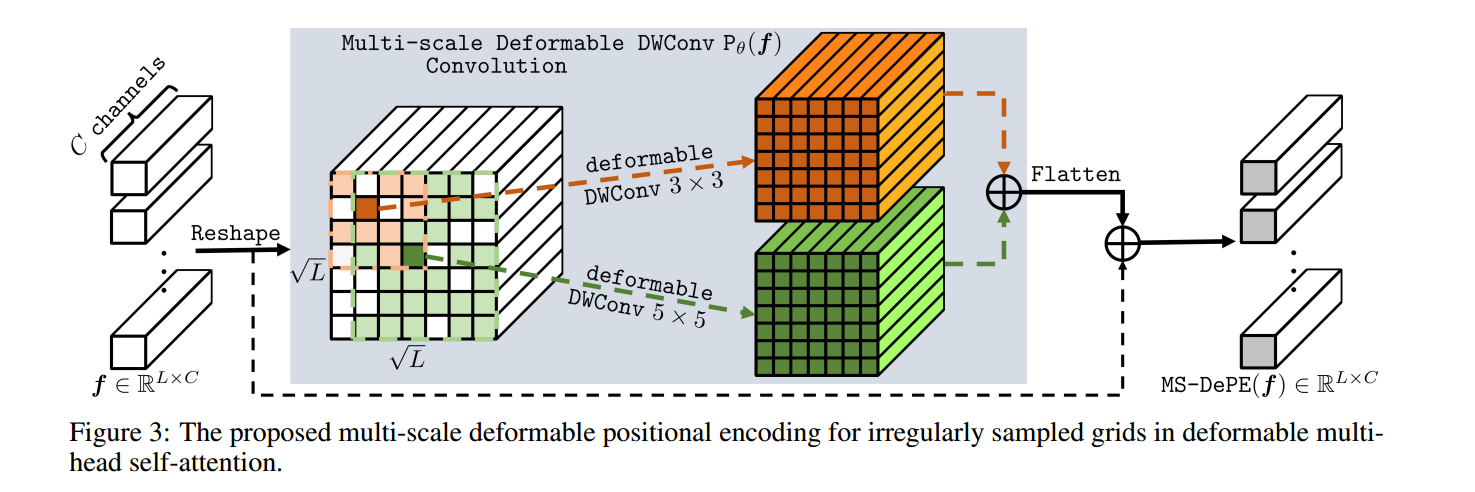
通过在跨多个尺度对不规则采样的位置信息进行编码。
公式如下:
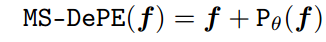
注:f是输入特征图,实现为多尺度可变形深度卷积层,具有不同的核大小(3×3和5×5)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 丹青两幻!
相关推荐



评论

