
TransNeXt
TransNeXt
论文:《TransNeXt: Robust Foveal Visual Perception for Vision Transformers》(CVPR 2024)
网络结构
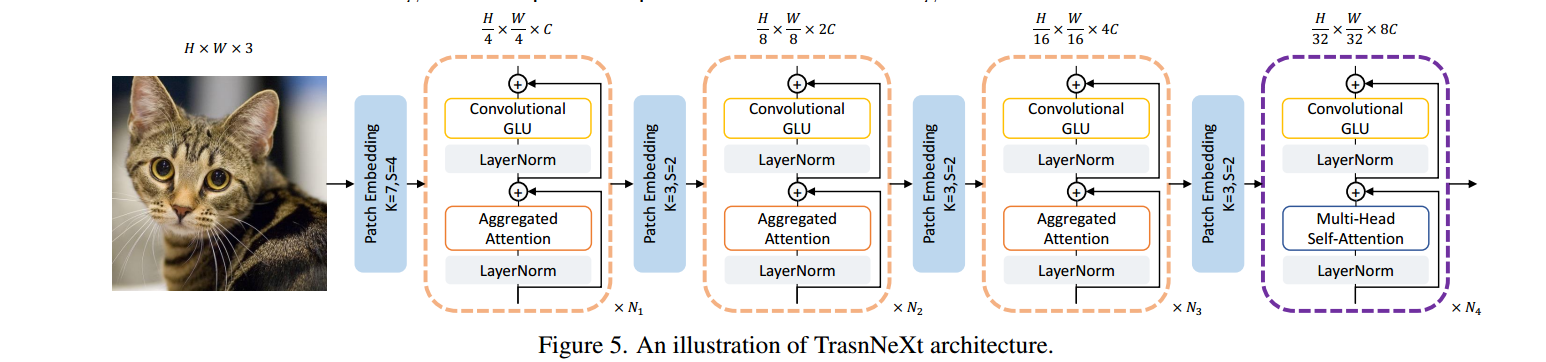
像素聚焦注意力机制:在每个查询附近具有细粒度感知,同时保持对全局的粗粒度感知(结合了滑动窗口注意力和集中注意力)
像素聚焦注意力(pixel-focused attention (PFA) )具体过程如下:

注1:定义输入特征图上以 为中心的滑动窗口中的像素集合为 。对于固定的窗口大小 , 。同时, 作者定义从特征图池化得到的像素集合为的 σ() 。对于池化大小 ,。
注2:PFA由滑动窗口注意力和池化窗口注意力两部分组成
池化:平均池化操作会严重丢失信息,所以在池化之前使用单层神经网络进行投影和激活,提前压缩提取有用的信息,从而提高下采样后的信息压缩率
下采样算子(Activate and Pool)如下:
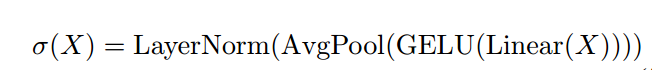
LKV通过添加一个可学习的查询嵌入(QE),来聚合多样的注意力:
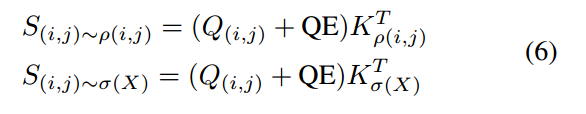
QLV破坏了键和值之间的一对一对应关系,使当前查询学习更多的隐式相对位置信息
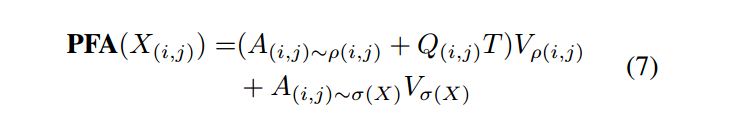
长度缩放余弦注意力:可以有效增强视觉模型的训练稳定性
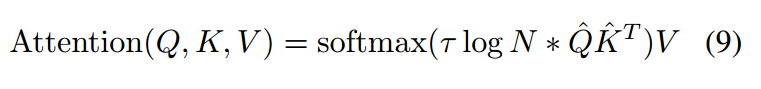
注1:注意力设计应表现出熵不变性,以促进对未知长度的更好泛化,是为了保持熵的不变性和忽略常数项。
注2:是可学习参数,N表示每个查询交互的有效键的计数(在本文中N为),是L2正则化后的结果
位置偏置:
- 池化特征路径:log-CPB方法,即使用一个具有 ReLU 激活函数的 2 层 MLP 来计算从查询点到空间相对坐标之间的位置偏差
注:池化使得特征的空间信息变得模糊或丢失,直接使用可学习的位置偏差可能无法有效地捕获到像素级别的位置偏差,所以使用对数间隔连续位置偏差(log-CPB)方法,通过 MLP 网络计算位置偏差,可以更好地捕获到细粒度的位置信息,从而提高模型对多尺度图像输入的泛化能力。
- 滑动窗口路径:在这条路径上,作者直接使用了一个可学习的位置偏差 B(i,j)∼ρ(i,j)。
聚合像素聚焦注意力(AA):
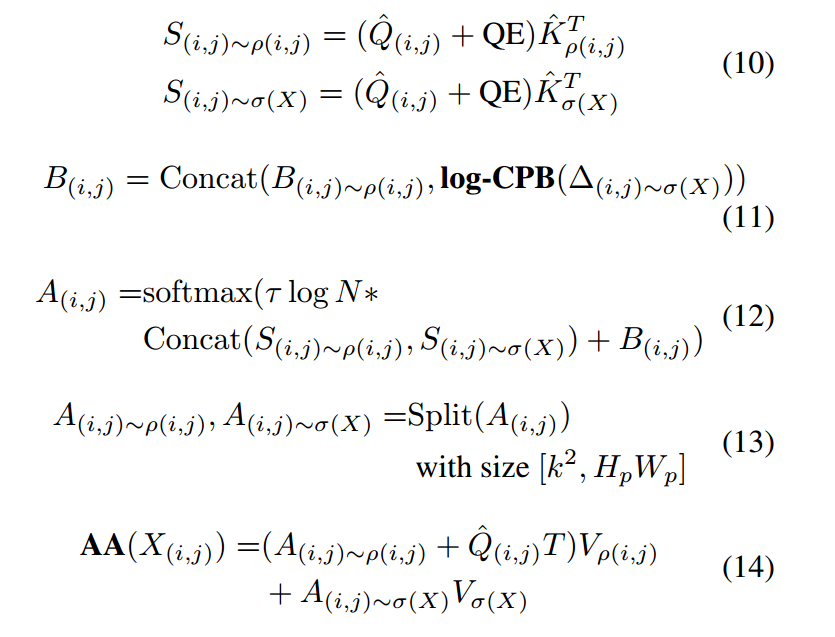
注:∆(i,j) ~ σ(X)为Q(i,j)和Kσ(X)之间的空间相对坐标
卷积GLU通道混合器:
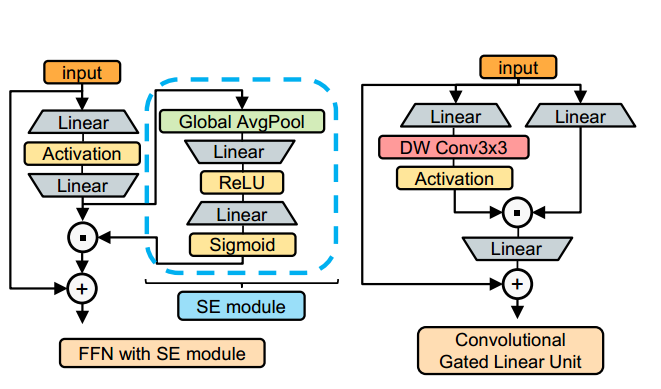
SE 机制的全局平均池过于粗粒度
卷积GLU通道混合器中的通道注意力是基于每个像素点的最近邻特征计算的(深度卷积),而且其可以提供一定的位置信息




