VSA
VSA: Learning Varied-Size Window Attention in Vision Transformers
论文:《VSA: Learning Varied-Size Window Attention in Vision Transformers》(ECCV 2022)
对于Swin Transfomer中的窗口注意力机制,如果窗口大小为可变的矩形窗口,其大小和位置直接从数据中学习,则transfomer可以从不同的窗口中捕获丰富的上下文,并学习更强大的对象特征表示。
VSA使用窗口回归模块根据每个默认窗口中的token来预测目标窗口的大小和位置
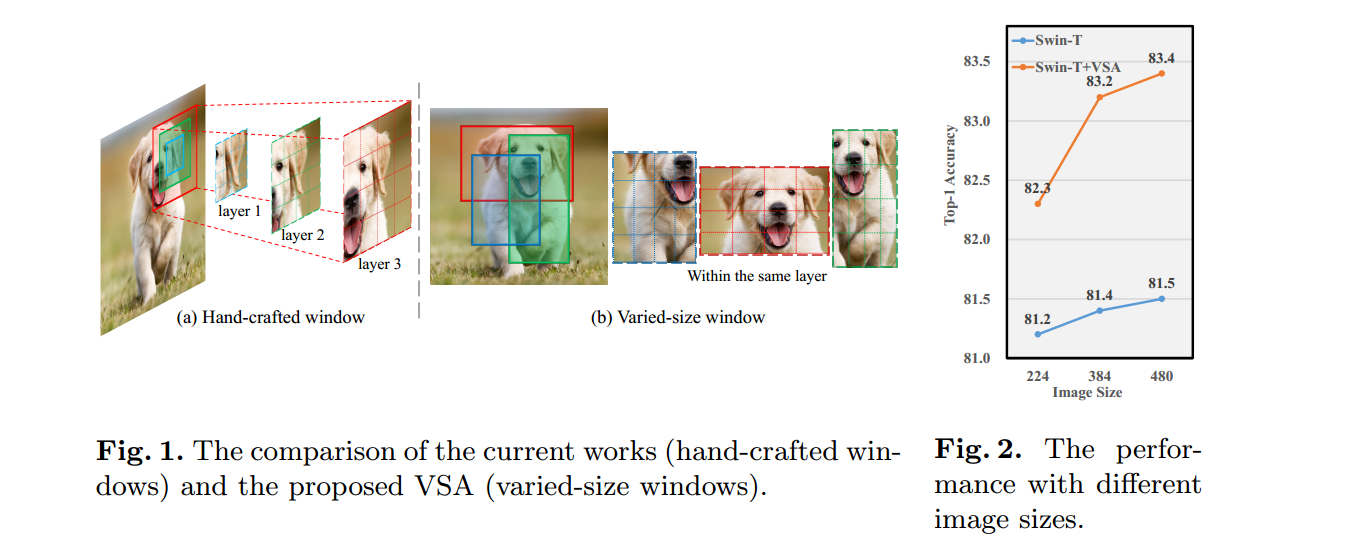
VSA将可学习的可变大小的窗口注意力引入到Transformer中
Varied-size window attention (VSA)的注意力机制:VSA允许查询令牌(query tokens)关注远处的区域,并赋予网络确定目标窗口大小(即注意力区域)的灵活性
VSA先将输入特征划分为几个窗口,这些窗口的大小基于预定义的w,这样的窗口被称为默认窗口
然后从默认窗口获取查询特征:通过一个线性变换来实现

VSR模块:用于估计每个默认窗口的目标窗口的大小和位置
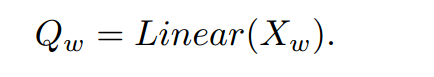
包括一个平均池化层(average pooling layer)、一个LeakyReLU激活层和一个步长为1的1×1卷积层,按顺序排列。池化层的核大小和步幅遵循默认窗口的大小。
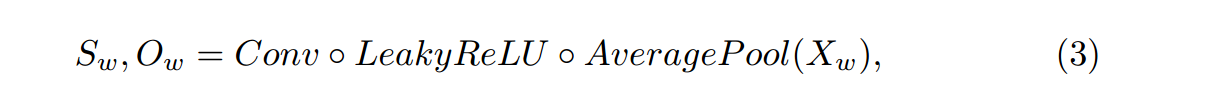
注1:表示目标窗口相对于默认窗口位置的水平和垂直方向上的缩放比例,是目标窗口相对于默认窗口的水平和垂直方向上的偏移量。
注2:,N为注意力头的个数
VSA的计算过程:
首先,从特征图X得到K、V:
注:
VSA模块分别在K、V上从每个不同大小的窗口(目标窗口)均匀采样M个特征,M设为w*w来使其计算的复杂度和窗口注意力相当。
对于Q、K、W进行注意力计算
注:由于K、V是从不同的位置采样得到的,因此使用相对位置嵌入可能无法很好地描述空间关系,所以在MHSA层之前采用条件位置嵌入(CPE)《Conditional positional encodings for vision transformers.(2021)》将空间关系提供给模型。
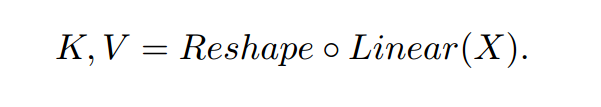
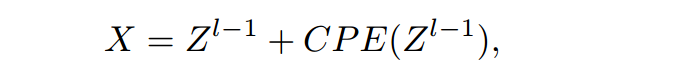
注:为前一个Transformer的输出特征,CPE由一个深度卷积层实现,其核大小设为窗口大小
模型的网络结构如下: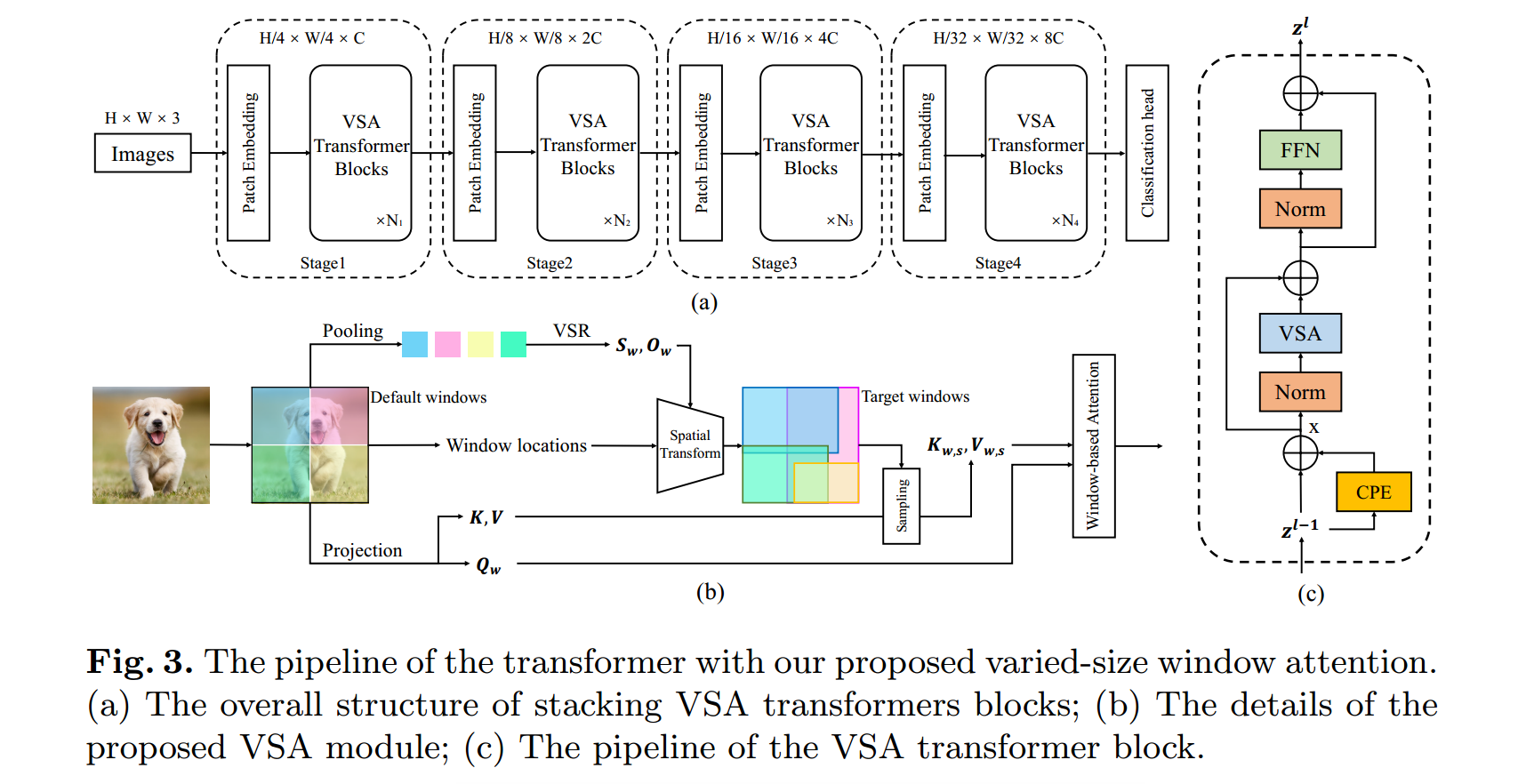
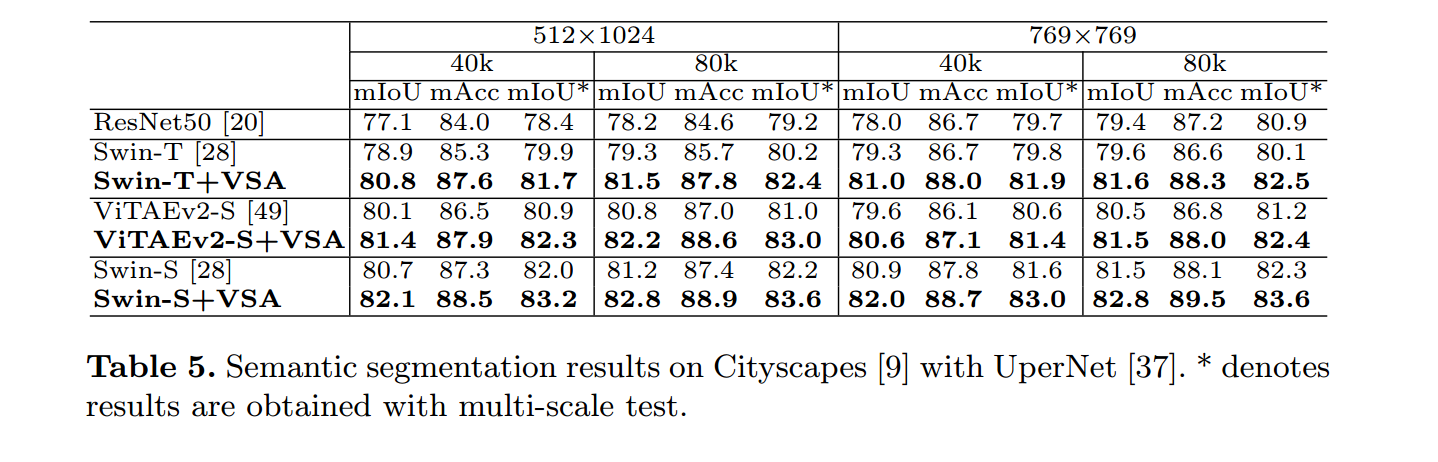
实验
对于语义分割任务:VSA模块可以提高baseline的性能