
DELIGHT DEEP AND LIGHT-WEIGHT TRANSFORMER
DELIGHT
论文:《DELIGHT DEEP AND LIGHT-WEIGHT TRANSFORMER》
DeLighT比标准的基于Transfomer的模型具有更少的参数,在每个Transformer块中使用DeLighT转换
DeLighT架构促使在Transformer中用单头注意力和轻量级前馈层替代多头注意力和前馈层,从而减少了总网络参数和运算。
注:在多头注意力中,每个注意力头都有自己的参数矩阵,因此总参数量较大。而使用单头注意力,参数矩阵只需一个,可以减少参数量。多头注意力需要对每个头进行独立计算,然后将它们合并,而单头注意力只需要进行一次计算,因此在计算上更加高效。
DeLighT Transformer
DeLighT变换:将一个维的输入向量映射到一个高维空间(Expansion),然后通过组线性变换(GLT)将其将维到一个维的输出向量(Reduction)。
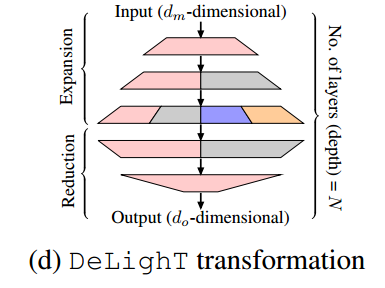
注:组线性变换(GLT)用于降低Transformer模型的计算复杂度,分成N个组,每个组共享权重矩阵,通过输入的特定部分来输出局部的特征表示,其比线性更高效
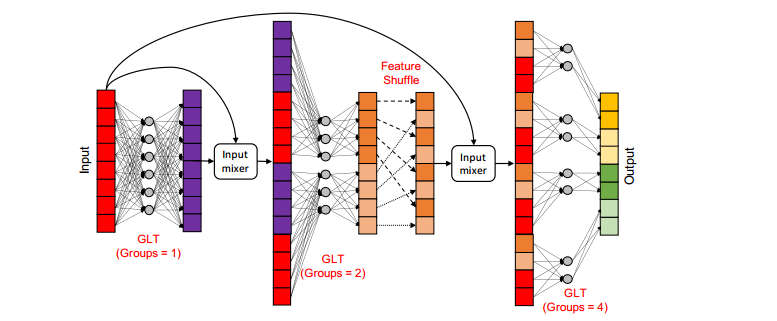
为了学习全局表示,DeLighT变换使用特征重排在组线性变换中共享信息。
模型表达能力的增加:传统Transformer增加输入维度以增加表达力,而为了增加DeLighT块的表达力,不是增加输入维度,而是通过Expansion和Reduction阶段增加中间DeLighT变换的深度和宽度。这使得我们可以使用更小的维度来计算注意力,从而需要更少的操作。
注:DeLighT变换的配置参数:GLTs的层数N、宽度乘法器、输入维度、输出维度和GLTs的最大组数
DeLighT变换具体步骤如下:
- Expansion:将维输入投影到高维空间,
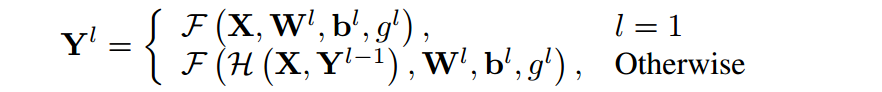
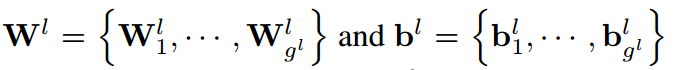
注:
- 为GLT的层数,表示层的组数,W、b为可学习的权值和偏置
- 函数将输入分为组然后进行线性变换得到Y
- 函数首先对进行重排,来增加不同组间的信息的交互,然后将其和X进行混合
下图显示了DeLighT转换中的扩展阶段:
DeLighT Block:一个包含n个输入token的序列,每个标记的维度为。这些n个维的输入首先被送入DeLighT变换,产生n个维度为的输出,其中。这些n个维的输出同时经过三个线性层投影,产生维的查询Q、键K和值V
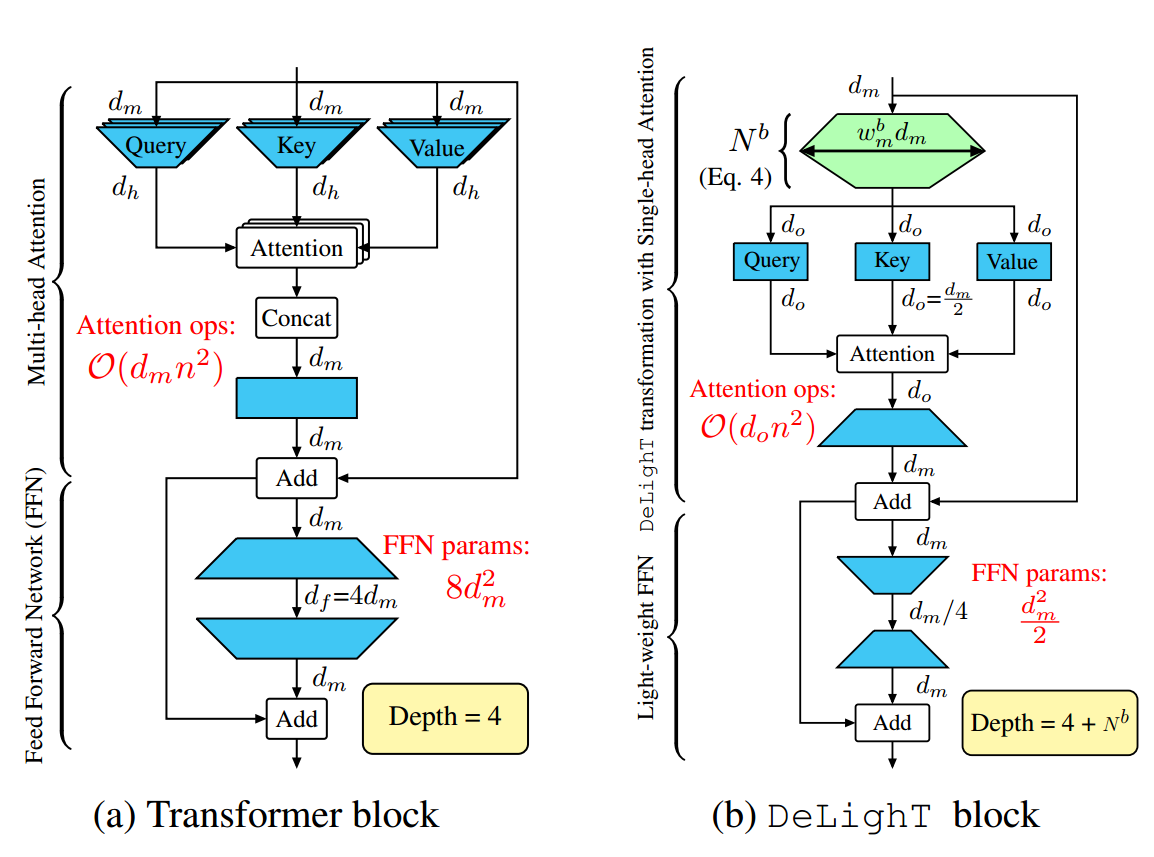
注:该模块将计算注意力的成本降低了,作者取
Light-weight FFN:r为降维因子,第一层将输入维度降维到,第二层将再扩展到,相比于Transformer减少了FFN的参数和计算量
块的扩展
与Transformer block相比,DeLighT block块的深度更深(N+4)
提高模型性能的方法通常通过增加模型维度(宽度缩放)、堆叠更多的块(深度缩放),然而这种方式在小数据集上不是很有效。
作者认为这是因为缩放模型的宽度和深度在块之间是均匀分配参数的,这会导致模型学习到冗余的参数,于是作者将模型缩放扩展到块的级别
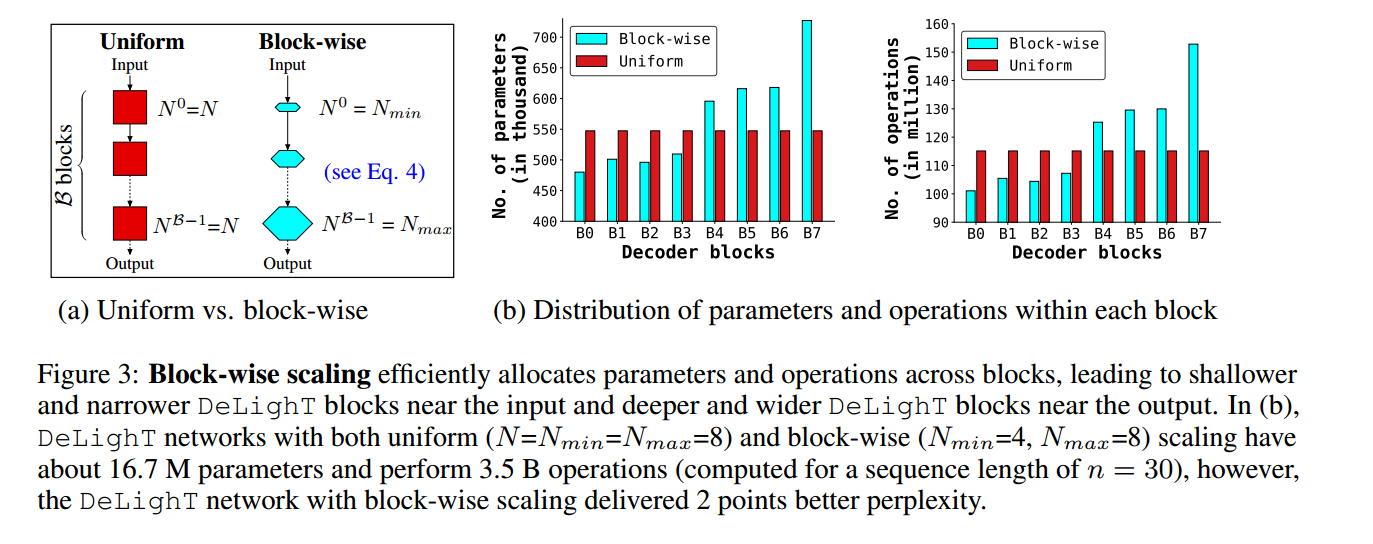
缩放DeLighT块:其深度和宽度分别由两个配置参数控制:GLT层数和宽度乘法器,通过引入了逐块缩放,创建了一个具有可变大小的DeLighT块的网络,在输入附近分配较浅和较窄的DeLighT块,在输出附近分配较深和较宽的DeLighT块。




