
卷积编码位置信息
论文:《HOW MUCH POSITION INFORMATION DO CONVOLUTIONAL NEURAL NETWORKS ENCODE?》(ICLR2020)
论文内容:
初步实验:
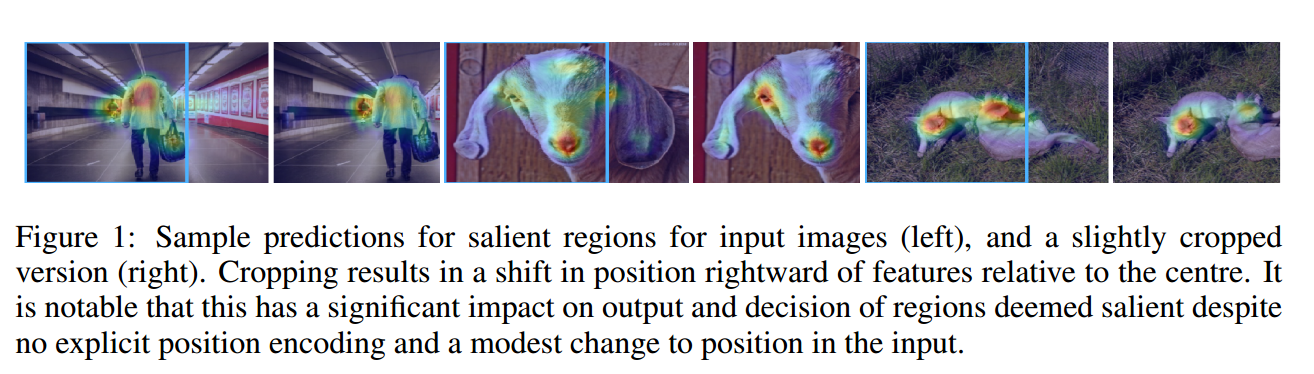
对原始图像和裁剪过的图像进行显著性检测。
显著的区域分析,对于相同的物体,在不同的边缘下,显著性区域始终靠近图像中心。
推测:位置信息在 CNN 网络提取的特征图中被隐式编码
Position Encoding Network:
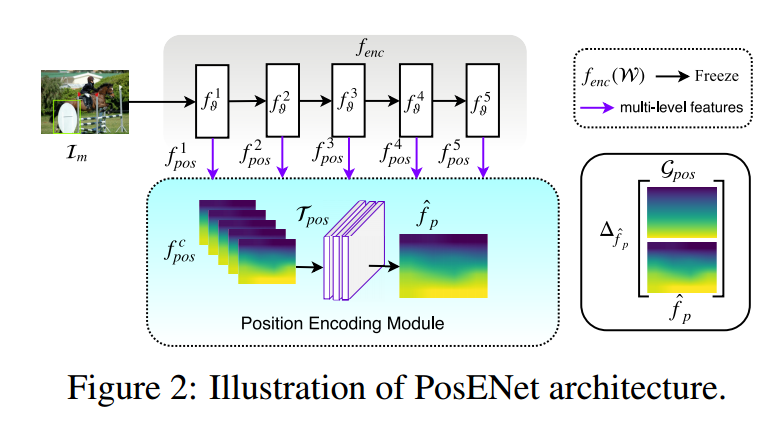
a feed forward convolutional encoder network $f_{enc} $:使用预训练的VGG或者 ResNet,仅作为前馈网络,其参数不参与训练。为前馈网络的在五个卷积层产生的特征图,使用双线性插值缩放到统一尺寸进行拼接,之后输入到 Position Encoding Module 中。
position encoding module:一般卷积网络,其卷积核未使用Padding。
作者使用该网络判断卷积层产生的特征图中是否包含位置信息。
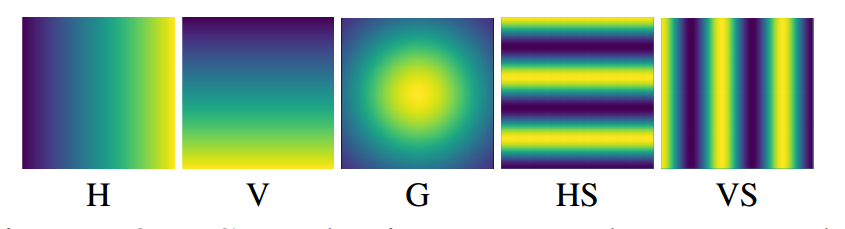
垂直(H)和水平(V)方向的梯度掩码、应用高斯滤波器来设计另一种类型的真值图,高斯分布(G)、水平和垂直条纹(HS、VS),使用这五种图像表示位置信息,作为Ground Truth,每次训练选择其中一种,所有样本的标签都是一样的
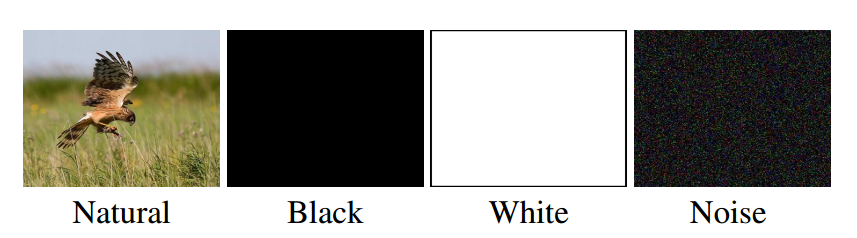
除了使用数据集中的原始图像,作者还分别将纯黑、纯白、高斯噪声图像作为输入,这是为了验证在没有语义信息的情况下,特征中是否包含绝对位置信息。
评价指标: Spearmen Correlation (SPC) and Mean Absoute Error (MAE),前者越高说明输出与目标图像的相关性越高,后者则相反。
实验结果:
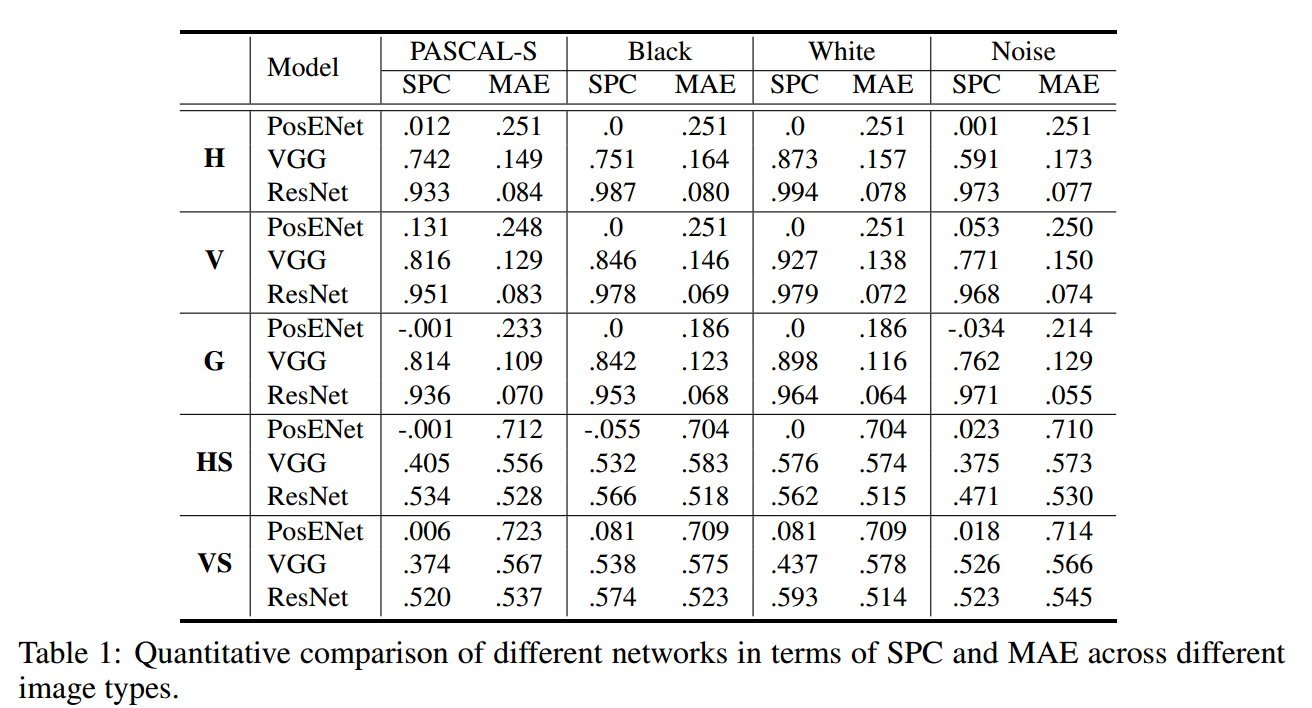
单独使用PosENet得到的分数要低很多,这一结果表明,仅从输入图像中提取位置信息是非常困难的,PosENet要与编码器网络相结合才能更好地提取出位置信息
发现基于ResNet的模型比基于VGG16的模型实现了更高的性能。
探究卷积的参数对提取位置信息的影响
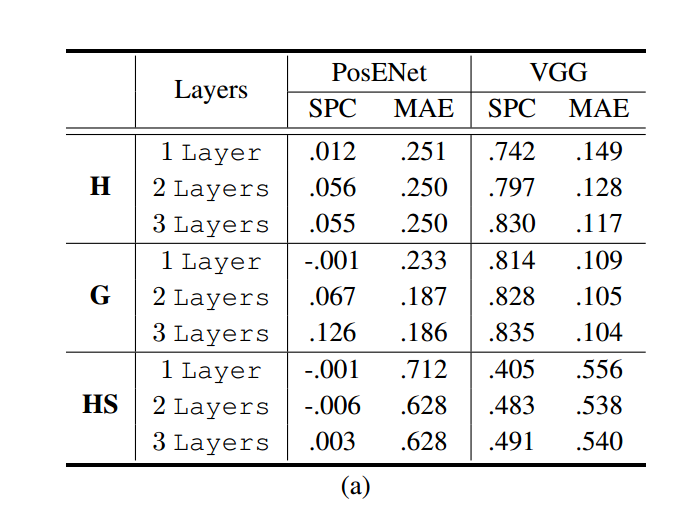
length of convolutional layers:
kernel size:
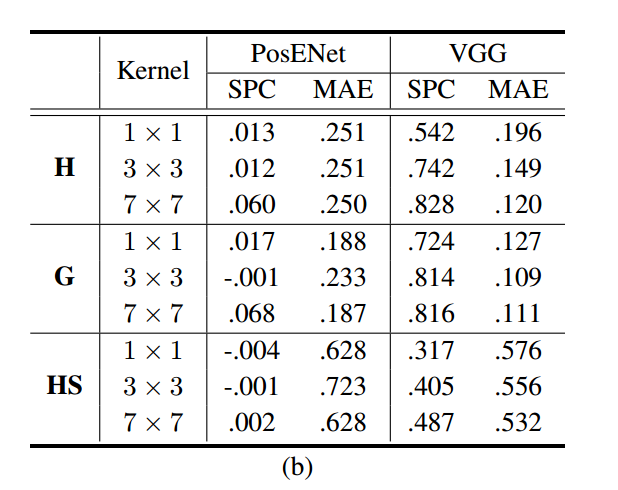
更大的感受野可以更好地解析位置信息
zero-padding:作者认为卷积中zero-padding 是 CNN 中位置信息的来源
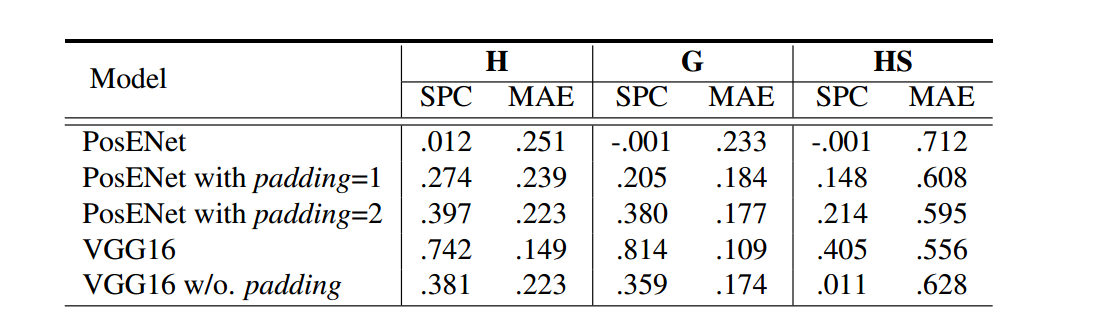
从结果中可以看出,未添加 zero-padding 的 VGG16 的性能比默认设置(padding = 1)低得多。PosENet(padding = 1)实现了比原始(padding = 0)更高的性能,而当 padding 设置为 2 时,位置信息的作用更加明显。




