
MedNeXt
MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
论文:《MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation》(MICCAI 2023)
1.网络结构
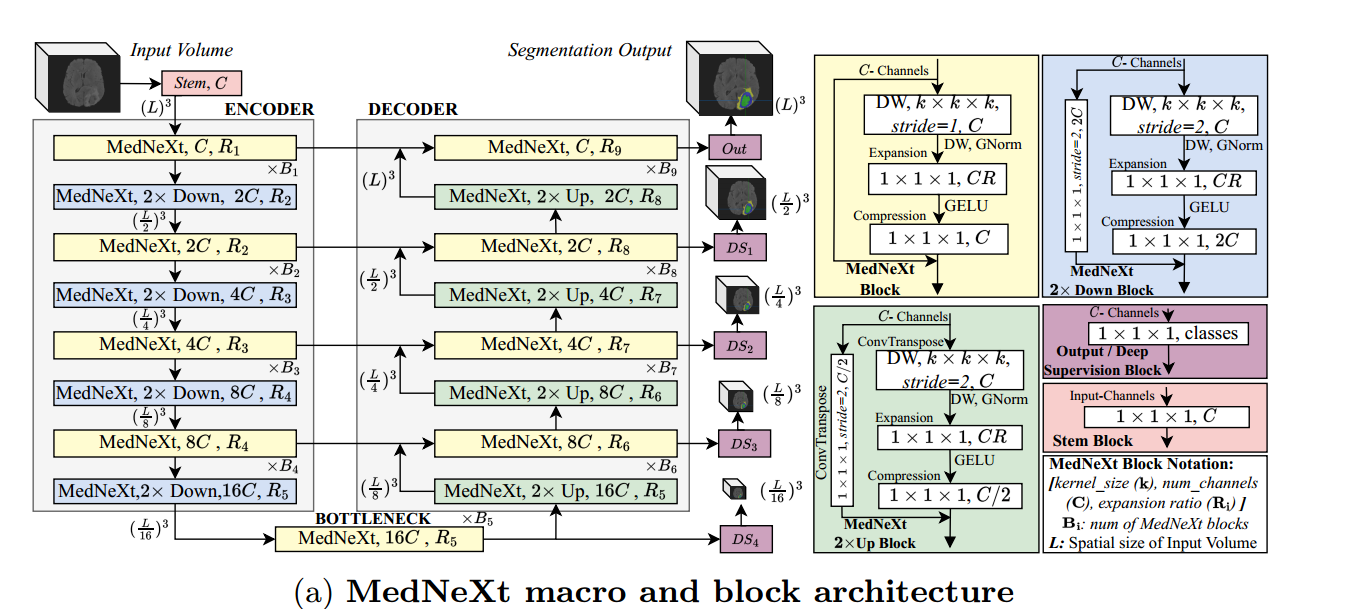
MedNeXt Block:
深度卷积层(DW):k × k × k的深度卷积,归一化使用channel-wise GroupNorm
Expansion Layer:较大的 R 值允许网络在宽度方向上扩展,而 1×1×1 核限制了计算量
Compression Layer:1×1×1卷积层对输出通道进行压缩
MedNeXt Down Block和MedNeXt Up Block:
- 添加了一个残差连接1×1×1卷积或转置卷积,步幅为2
解码器层使用深度监督,在较低分辨率下具有较低的损失权值(深度监督:在网络的中间部分添加了额外的loss,不同位置的loss按系数求和。深度监督的目的是为了浅层能够得到更加充分的训练,解决深度神经网络训练梯度消失和收敛速度过慢等问题。)
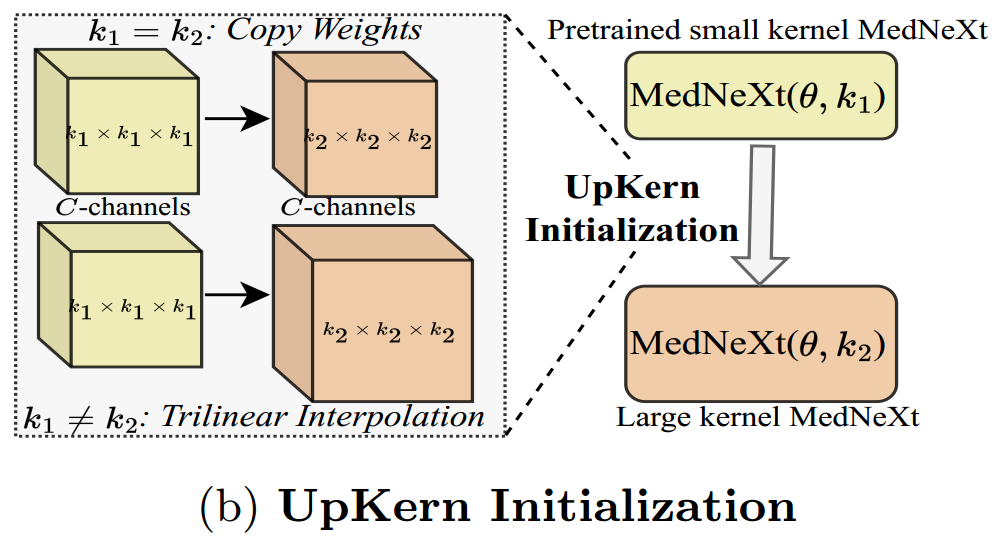
UpKern 初始化:
大卷积核的缺陷:大卷积核性能可能更容易达到一个瓶颈,无法再进一步提高。(大卷积核模型有更多的参数,因此更容易过拟合训练数据)
医学图像分割任务的数据少之又少,性能更容易饱和。
为了帮助大卷积核网络在医学图像分割等任务中更好地利用有限数据,从而改善性能。
对预训练小核网络进行三线性上采样来初始化大核网络,从而迭代地增加核大小。其他的大小相同的层(包括归一化层)都通过直接复制预训练层的权重来初始化。
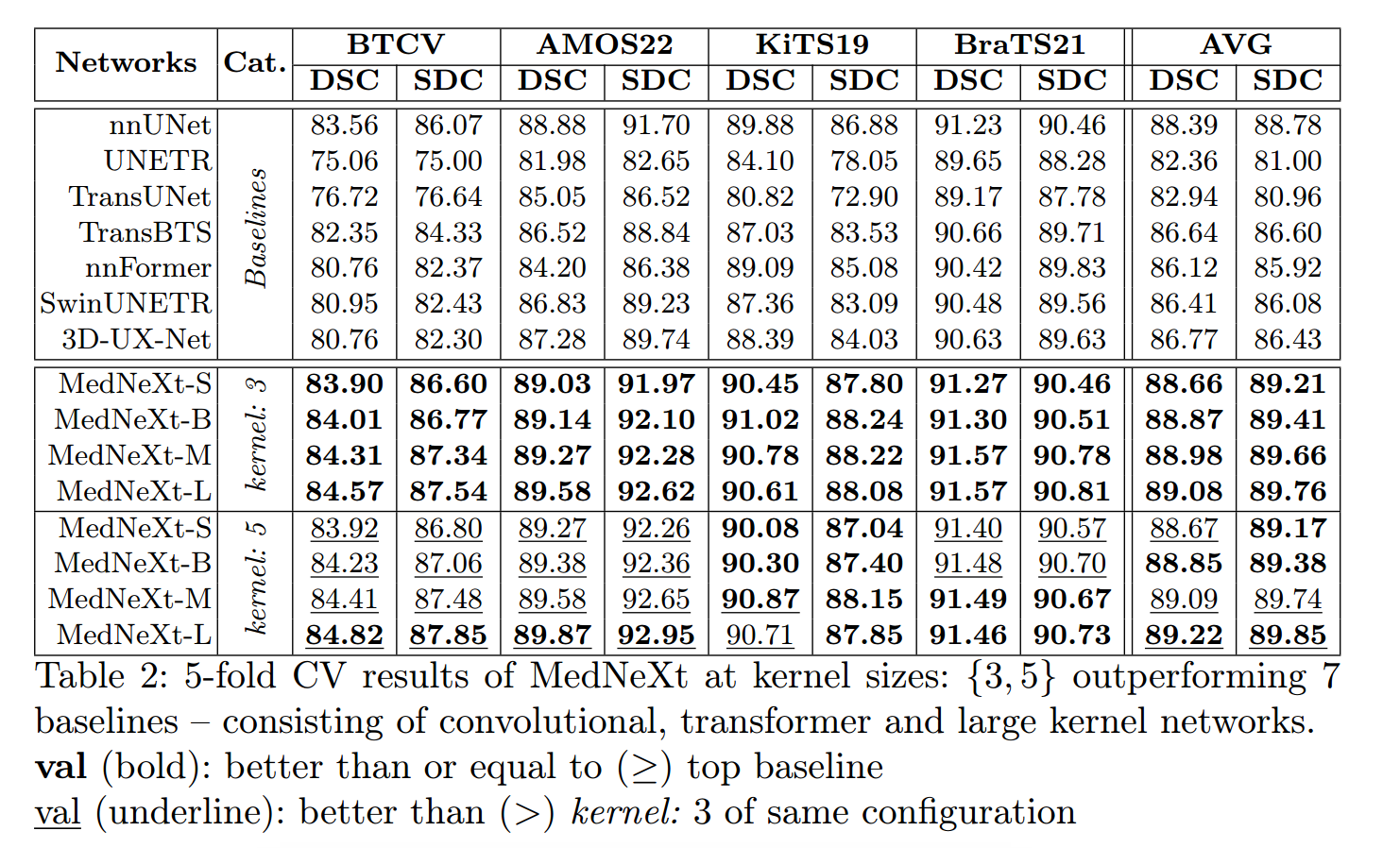
MedNeXt四种配置及消融实验:

通道数(C)均设置为32
- 在重采样时保留了特征映射中的语义丰富性
- 没有UpKern的大内核和小内核的性能是没有区别的
- 大卷积核中的性能提升是由于UpKern与大卷积核的结合,而不仅仅是更长的训练
2.实验结果
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 丹青两幻!
相关推荐



评论

