
Swin-Transformer
Swin-Transformer
1.网络结构
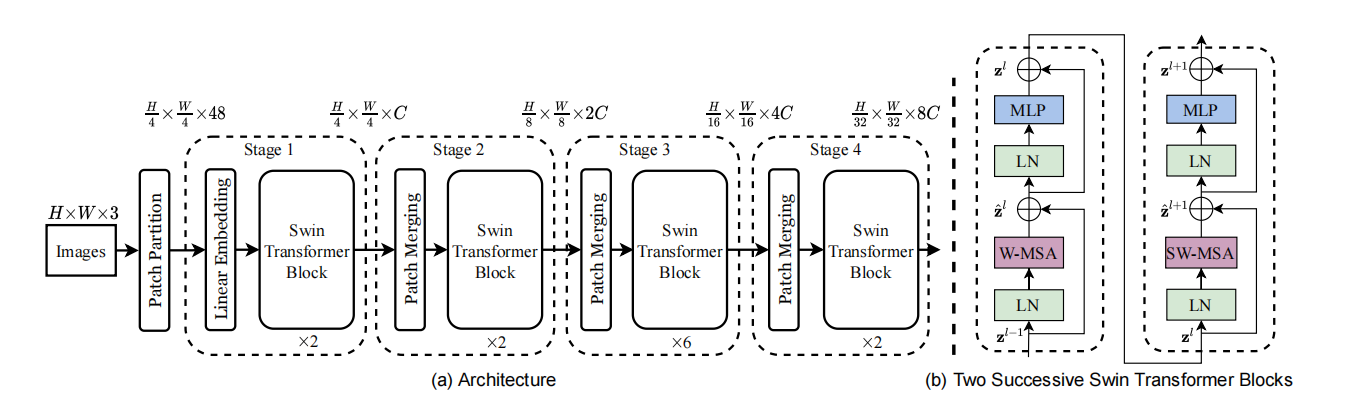
注:使用Transformer取代卷积操作是因为卷积操作在每个位置只关注输入图像的局部感受野,即一个固定大小的区域,而难以有效地捕捉全局信息,Transformer架构引入了自注意力机制,允许模型在一定范围内建立像素之间的关联,可以更好地处理全局信息。
2.W-MSA
使用窗口多头自注意力,将输入的图片划分成不重叠的窗口,在这样的局部的窗口中计算自注意力,减少计算量,其对于图像的大小具有线性的复杂度
$Ω(MSA) = 4hwC^2 + 2(hw)^2C; (1)$
$Ω(W-MSA) = 4hwC^2 + 2M^2hwC; (2)$
注:
h,w:输入图像的高,宽
M:一个窗口中含有MxM个patch
C:超参数(linear embedding将patch的特征维度变成C)
3.SW-MSA
虽然基于窗口计算自注意力能够很好的解决计算量大的问题,但是现在窗口与窗口之间没有联系,就达不到全局建模的能力,所以作者就提出了移动窗口的方式去解决
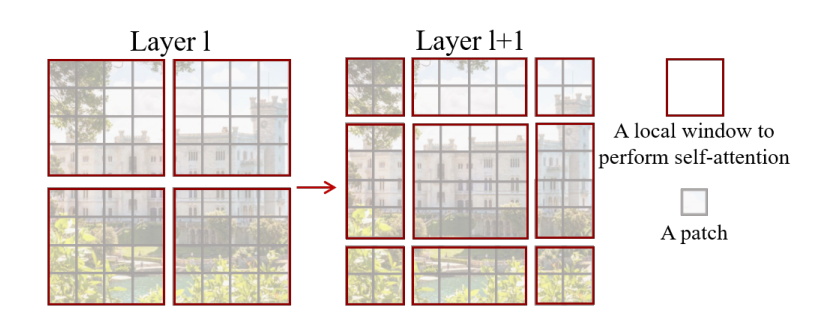

从Layer1移动到Layer1+1后存在的问题:每个窗口中的patch数量不同,窗口数增大了,会影响计算效率
解决方法:cyclic shift+MSA-masked
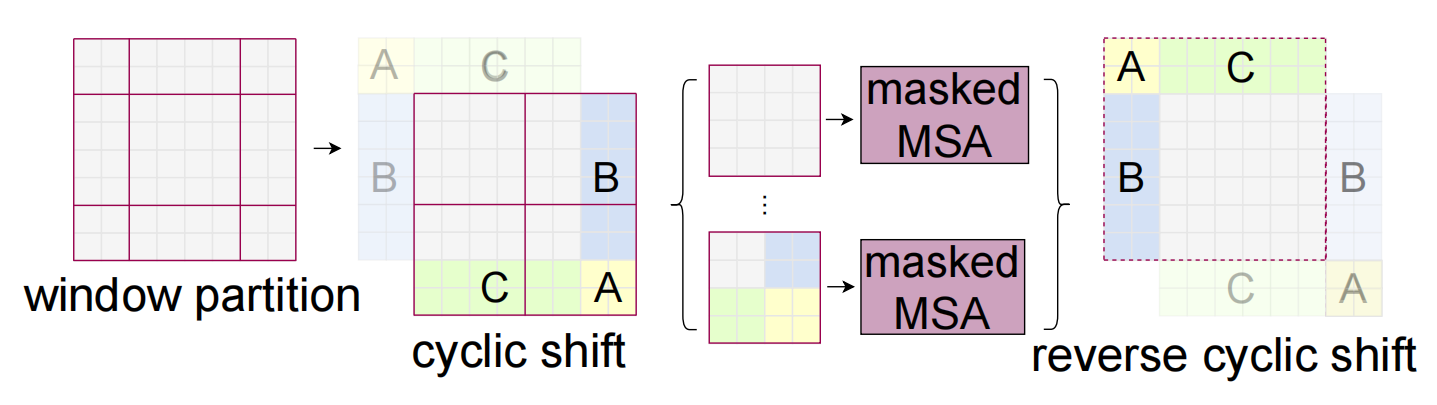
循环移位:将A、C先向下拼接,再将B、A向右拼接。通过循环移位将窗口的数目再一次地拼成4个,控制了计算复杂度,但产生了新的问题:同一个窗口中的patch来自于不同的区域,而来自于不同区域的patch之间不应该计算自注意力。
MSA-masked:对于一个patch,得到这个patch的attention(Q、K、V),将这个patch的Q与其他patch的K点乘,如果这两个patch来自于不同的区域,那么将点乘的结果减100,那么结果将是一个负数,再经过softmax处理后映射得到的权值接近于0
4.patch merging
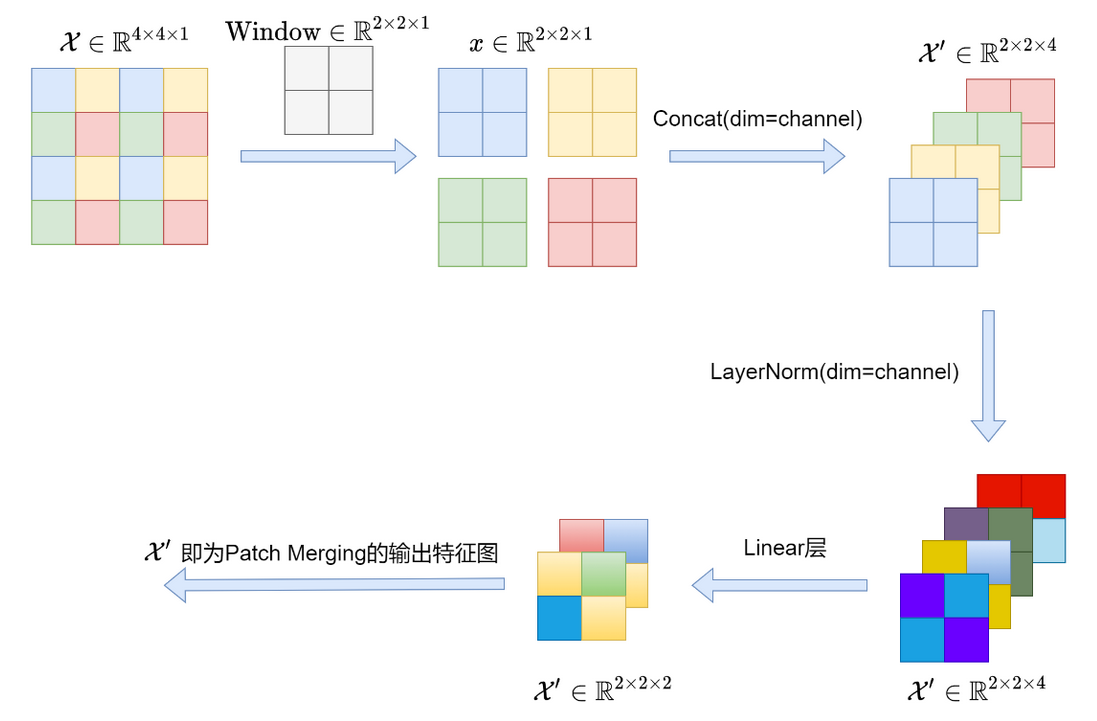
patch merging:进行下采样,用于缩小分辨率,调整通道数进而形成层次化的设计
5.Relative position bias(相对位置偏置)
偏置B:让attention map进一步有所偏重,在进行Attention计算时考虑到像素间的位置关系。
偏置B是由将像素与像素间的相对位置进行编码然后通过查找偏置表得到的。

Swin-Unet
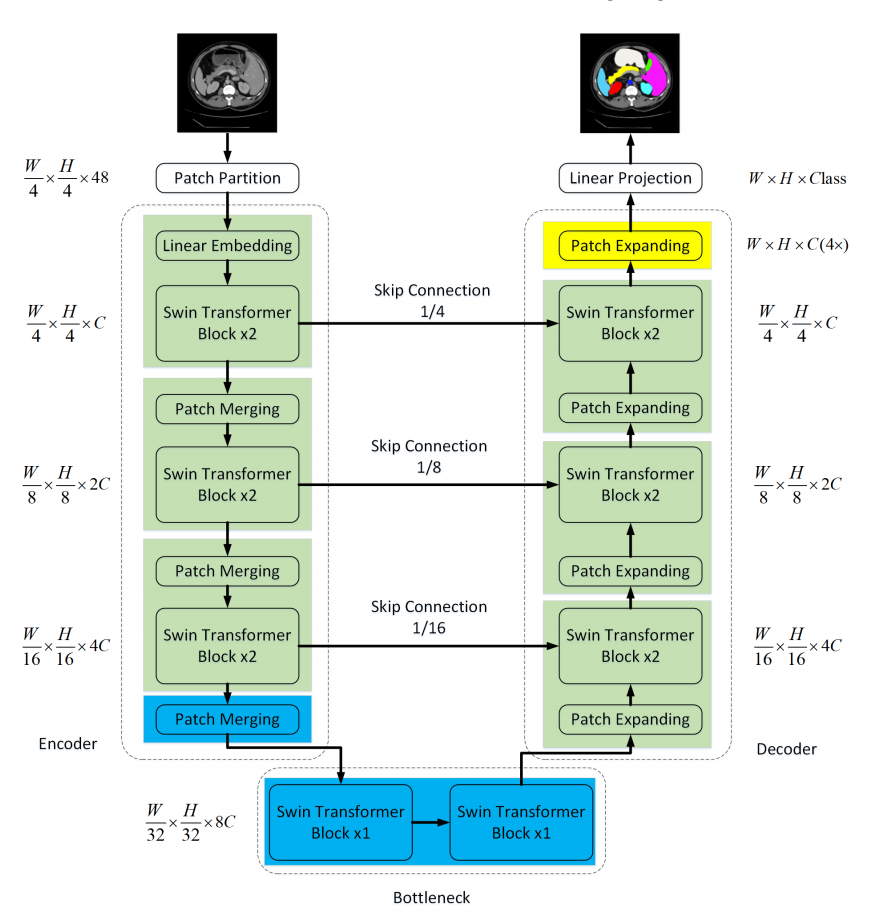
编码器:工作原理和 Swin-Transformer完全一样的。其中,Patch Merging模块的作用是在每个Swin-Transformer模块开头来降低图片分辨率。
解码器:Patch Expanding将相邻维度的特征图重塑为更高分辨率的特征图(2×上采样),并相应地将特征维数减半。
Patch Expanding:
在上采样之前,在输入特征上加一个线性层,将特征维数增加到原始维数的2倍,利用重排操作将输入特征的分辨率扩展为输入分辨率的2倍,将特征维数降低为输入维数的1/4。
1 | class PatchExpand(nn.Module): |




