
LHU-NET
LHU-NET: A LIGHT HYBRID U-NET FOR COST-EFFICIENT, HIGH-PERFORMANCE VOLUMETRIC MEDICAL IMAGE SEGMENTATION
论文:《LHU-Net: A Light Hybrid U-Net for Cost-Efficient, High-Performance Volumetric Medical Image Segmentation》(arXiv 2024)
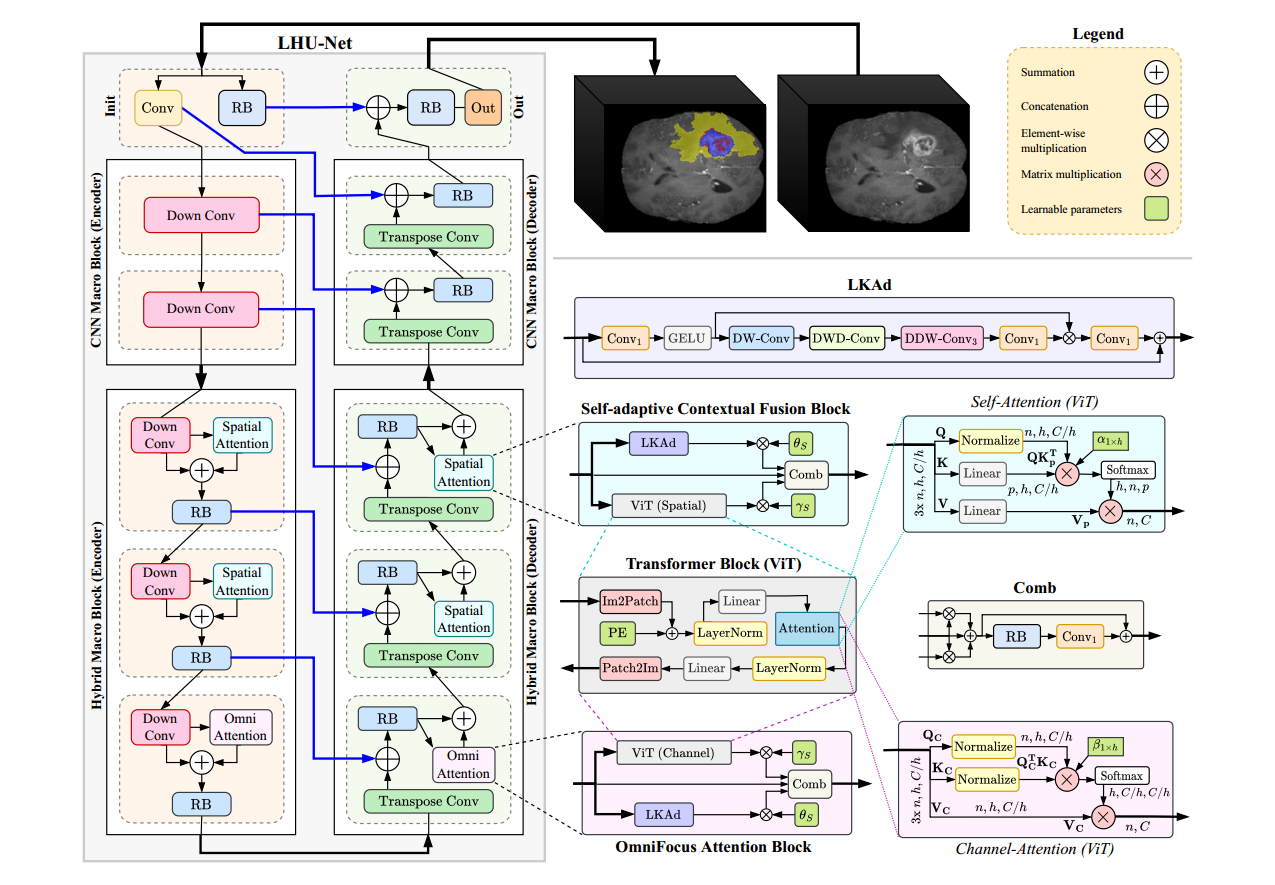
LHU-Net:将基于卷积的块与混合注意力机制集成
Init 阶段与Out阶段:
- 该阶段从一个点卷积操作(PW-Conv)开始,应用于输入数据,调整通道维度以匹配后续级别的通道数。

同时对于输入直接应用ResBlock,将其输出输入到Out阶段,与解码器的输出进行连接,产生最后的结果


注:表示CNN解码器块输出
CNN Blocks:
初始空间维度需要大量的计算成本,Vit难以应用,故在此阶段的设计是为了优化参数效率和保留局部特征,在之后的阶段再提取全局特征
- Down Conv块的设计如下:
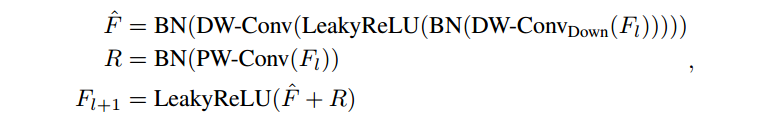
Hybrid Blocks(混合注意力):
在此阶段将局部细节和全局信息进行融合
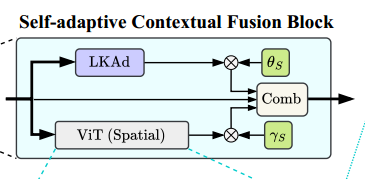
Self-Adaptive Contextual Fusion Module:将空间注意力模块与卷积模块相结合,这种空间注意力模块将LKAd模块与自注意力机制的输出进行并行计算
该模块最终的输出为:
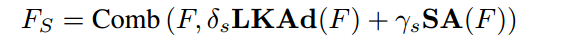
注1:和表示每个通道的可学习参数,控制两种不同注意机制的组合权值
注2:Comb函数的定义如下:DW-Conv3 是一个 3×3×3 的卷积块
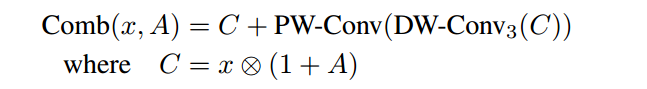
LKAd:
其步骤如下:
- 输入经过一个点卷积操作(Conv1),然后应用激活函数(GELU),以引入非线性和降低维度。
- 变换后的张量经过一系列深度卷积(DW-Conv)和深度膨胀卷积(DWD-Conv)操作,以提取多尺度特征并保留空间信息。
- DDW-Conv3集成了可变形深度卷积可以自适应地对特征图进行采样,从而增强了模型捕获细粒度细节和长距离依赖的能力。

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 丹青两幻!
相关推荐



评论

