
nnFormer
nnFormer
论文:《nnFormer: Volumetric Medical Image Segmentation via a 3D Transformer》(TMI2022)
1.网络结构
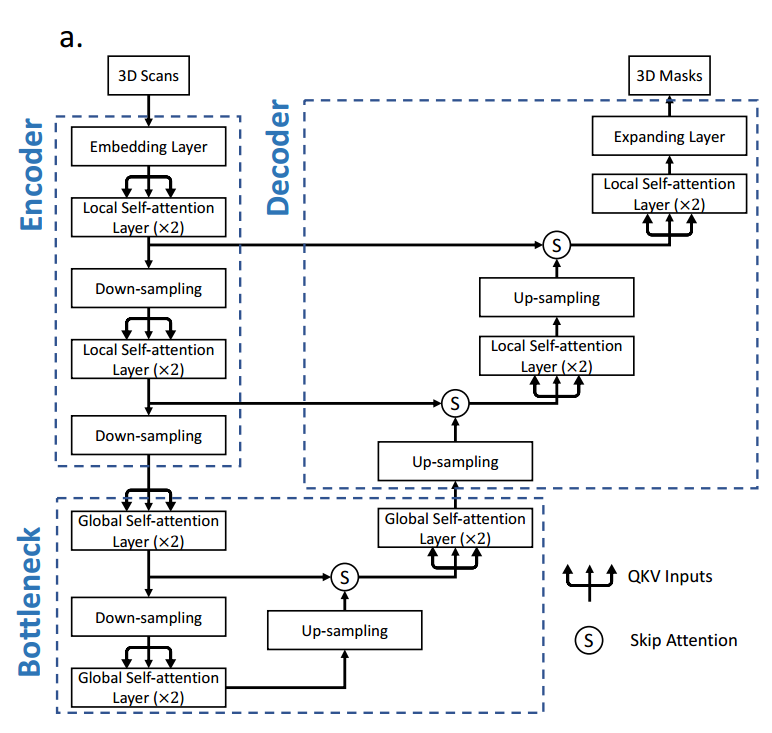
编码器
nnFormer的输入:对原始图像中随机裁剪(HxWxD),数据增强技术,有助于模型更好地学习不同部分的特征。
The embedding layer:(将输入数据转换成高维张量)
- 使用卷积的好处:对比transformer使用线性层对patch的向量进行映射,卷积层能够更细致地捕获图像中的像素级信息(减少了训练的参数数量,卷积核在处理特定区域时更加专注)
- 在初始阶段使用小卷积核的连续卷积层,相对于大卷积核的好处:降低计算复杂度,同时保持相同大小的感受野(非线性激活函数多了,语义表达能力增强了)

注:根据输入的patch大小卷积步长也会有相应的变化
Local Volume-based Multi-head Self-attention (LV-MSA):将不同尺度的信息和高分辨率的空间信息相互关联
不同尺度的特征由下采样层生成,高分辨率的空间信息则由嵌入层编码
使用的是一种基于局部三维图像块的self-attention计算方式(跟Swin-UNet类似)
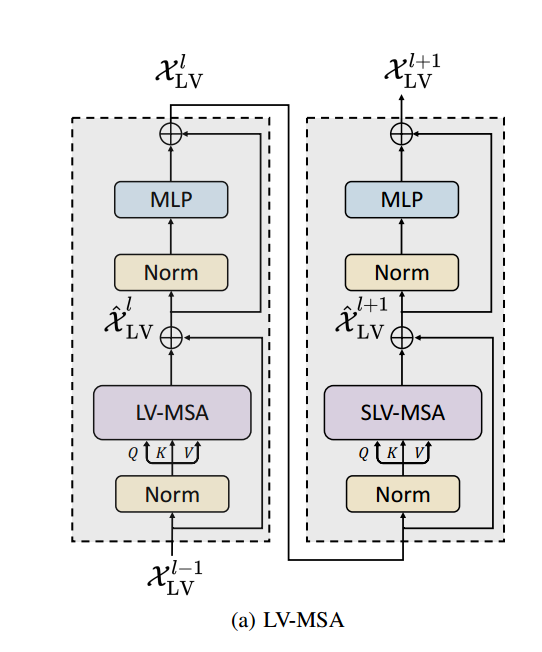
SLV-MSA:是LV-MSA的shifted版本(类似于Swin-UNet,目的是使局部的三维图像块之间产生联系)

注:$S_H、S_W、S_D$代表每个图像块中的patch的数量
使用LV-MSA减少了计算的复杂度,计算复杂度和图像之间是线性的关系

使用相对位置偏置B来引入位置信息
The down-sampling layer:
与Swin-UNet使用patch merging不同,作者选择了使用简单的卷积来实现下采样,卷积下采样可以在不同空间维度上应用不同的步长,以根据问题的要求调整下采样率。(可以根据数据的特点来灵活设置,避免过度下采样,对于三维的图像在某些维度上数据切片数量有限,这时可以将该维度的步长设置为1)
Bottleneck
不同于编码器使用局部自注意力机制,Bottleneck中使用全局自注意力。
计算复杂度:
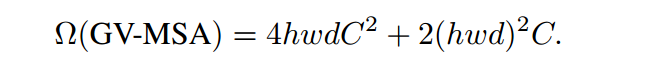
编码器部分减小了h、w、d,这为GV-MSA的应用创造了条件,与LV-MSA相比,GV-MSA能够提供更大的感受野
Decoder
上采样操作:使用转置卷积
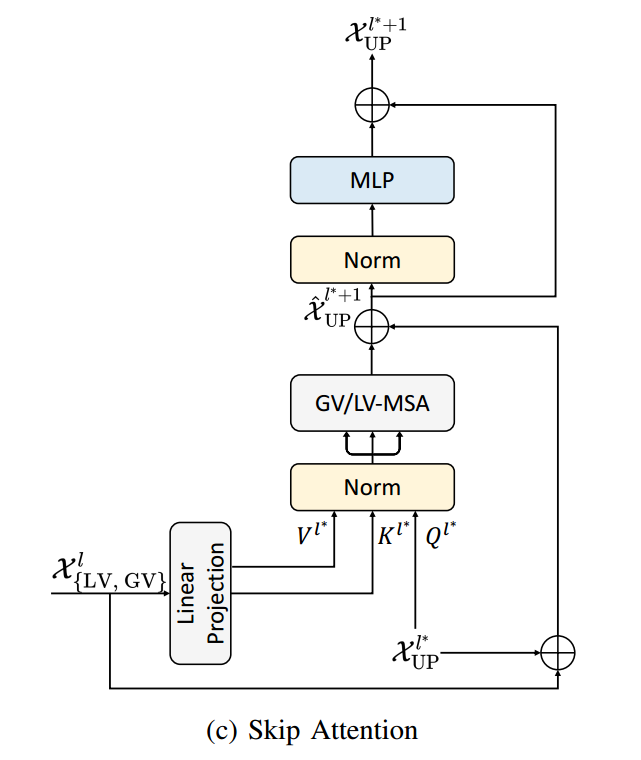
Skip Attention:(使不同层之间的信息交流变得更加灵活)
2.实验部分
与基于Transformer的方法学的比较
脑肿瘤分割
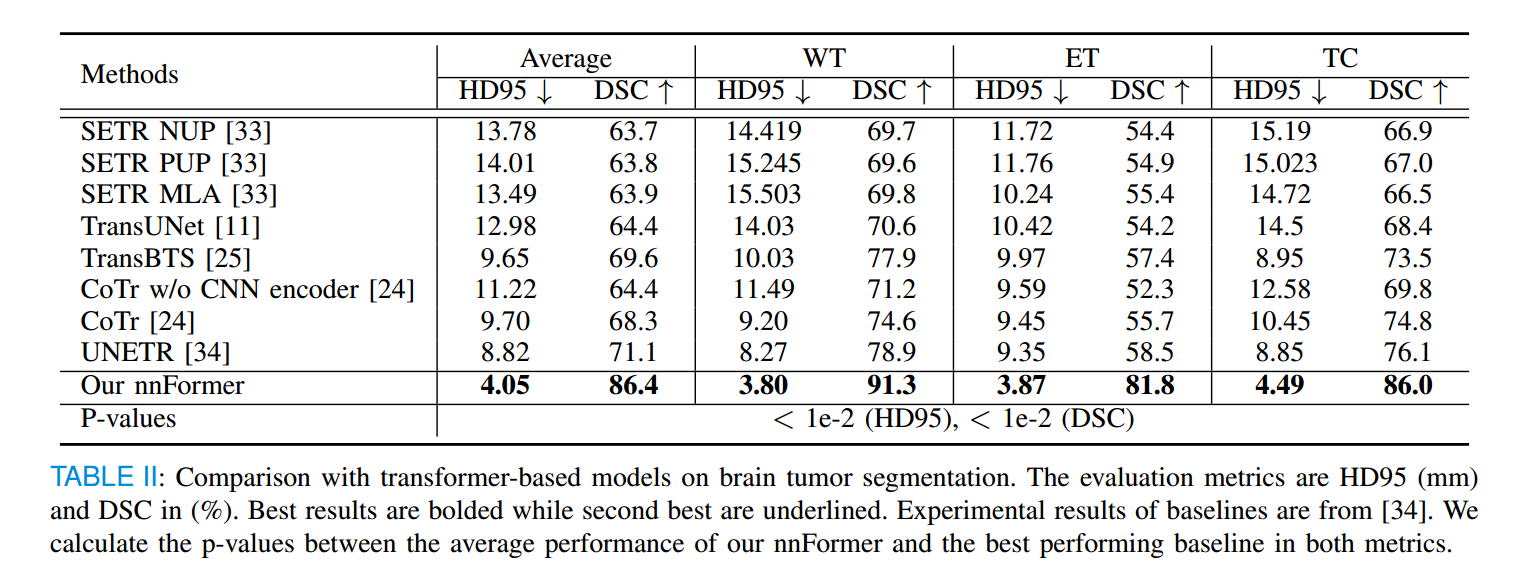
列出了所有模型在脑瘤分割任务上的实验结果,nnFormer在所有类别中取得了最低的HD95和最高的DSC分数。
多器官分割(Synapse)
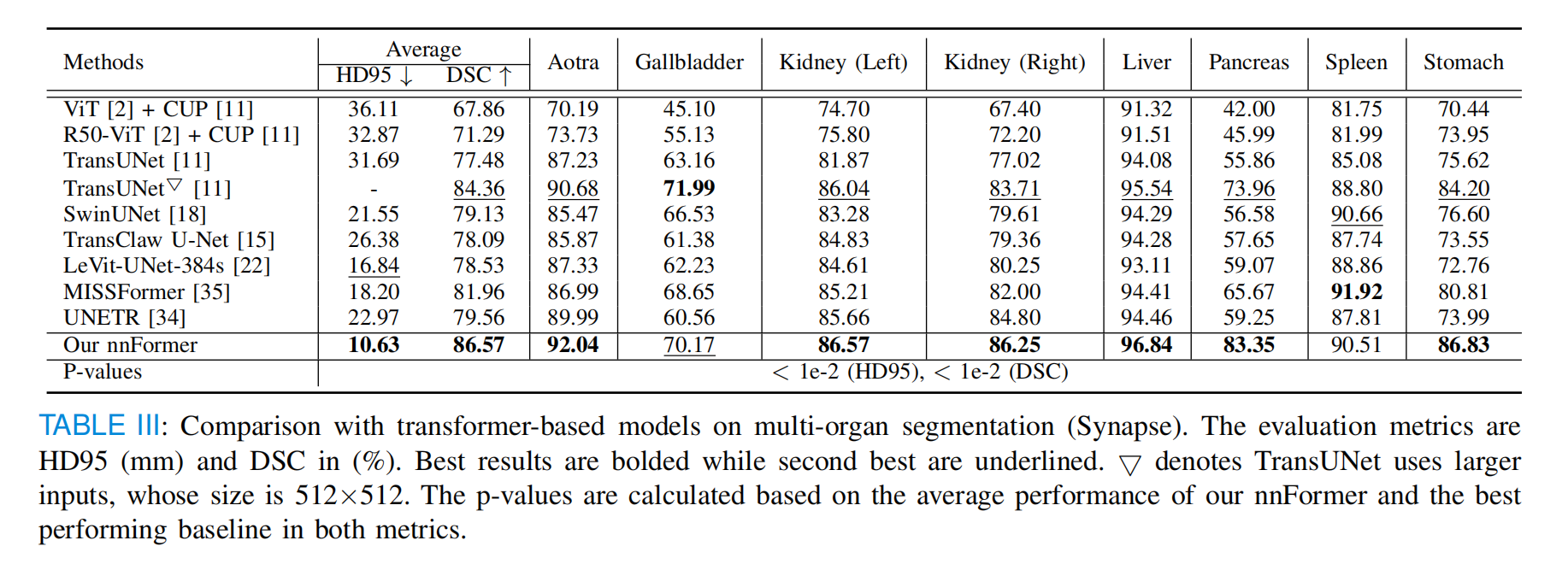
与以前基于Transformer的方法相比,nnFormer在分割胰腺(Pancreas)和胃(Stomach)方面更有优势
与nnUNet的比较
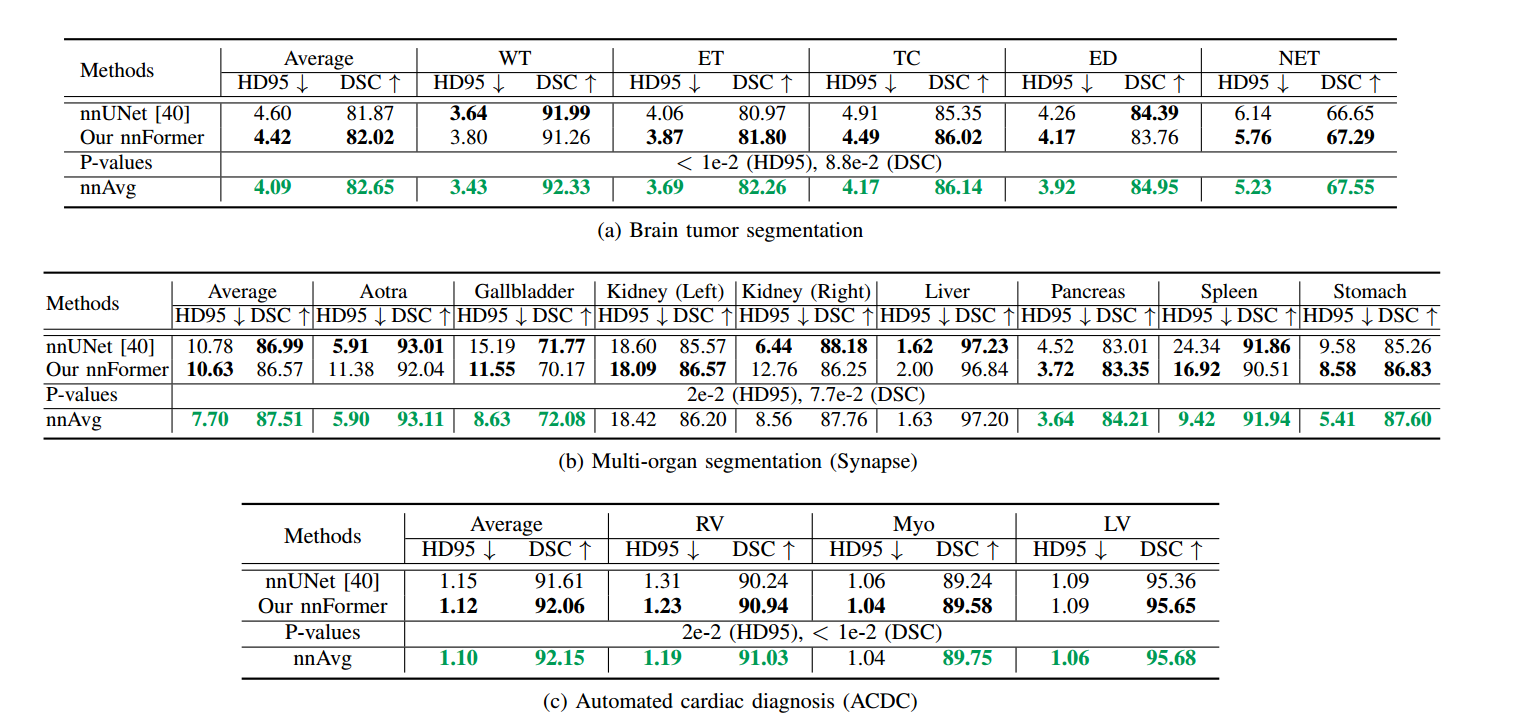
nnFormer的HD95似乎更有优势,其可以更好地划分对象边界。
nnAvg:对nnFormer和nnUNet的预测结果进行平均化,发现整体的性能得到了提高,表明nnFormer和nnUNet是可以互补的。
消融实验

嵌入层使用小卷积核大小的连续卷积层
卷积下采样层替换掉了patch Merging层
GV-MSA替换了Bottleneck的LV-MSA
Skip Attention代替跳跃连接
- SLV-MSA层与LV-MSA层级联,全局自注意力层的数量增加一倍




