SegFormer
SegFormer
1.网络结构
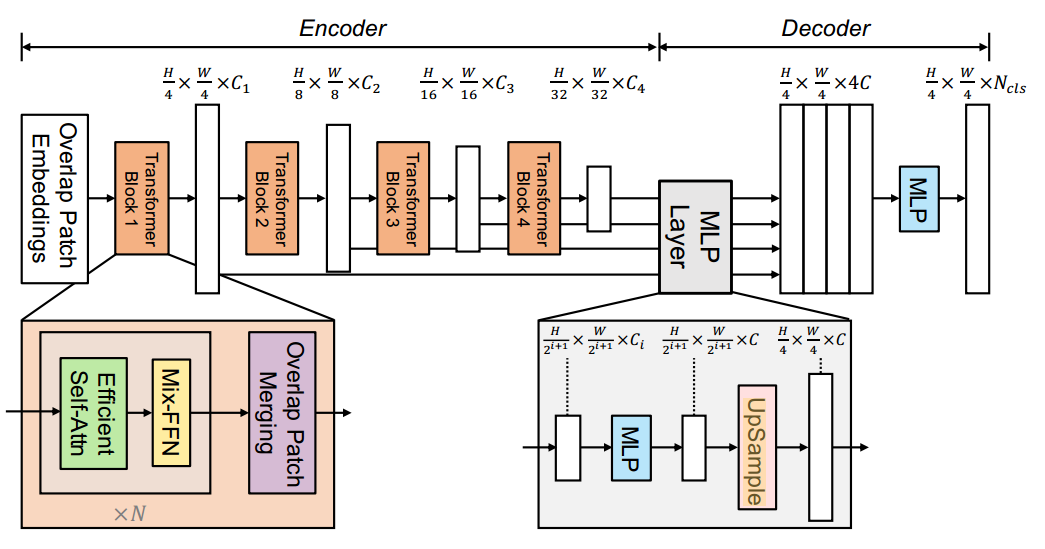
编码器:通过在不同阶段进行下采样,生成多尺度特征。
Efficient Self-Attention:
原始的自注意力计算:
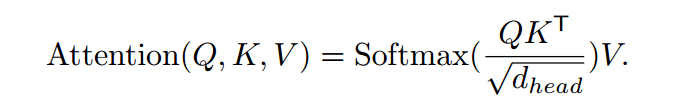
计算复杂度为O($N^2$),其中N为w*h
高效的自关注机制:通过一个压缩比R对K进行处理,改进的计算过程如下.0
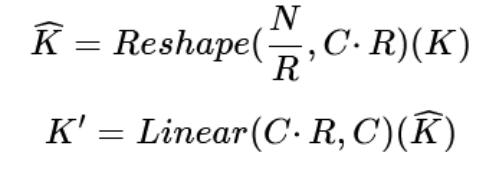
复杂度从O($N^2$)将至O($N^2 \over R$),降低了计算复杂度
注:论文中的R分别取64, 16, 4, 1
通过将K进行reshape将空间维度N的信息转移到通道维度C上,可以得到$\widehat K$;然后通过线性变换层将通道为降到原始维度C上,得到K’,实现空间下采样。
Mix-FFN:为了解决使用位置编码引入位置信息,但由于在测试时的分辨率发生变化时,会引起精度下降的问题。
注:训练时生成的位置编码长度小于预测时的需要时,一种处理方法是使用插值将训练时的位置编码扩展到预测时所需的长度。
位置信息在语义分割中不是必需的
Mix-FFN:直接使用3*3卷积捕获一定程度上的位置信息
计算过程如下:
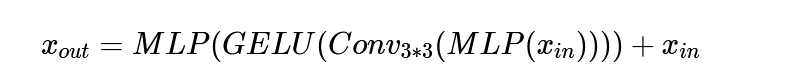
注:$x_{in}$为自注意力模块的输出
Overlapped Patch Merging:保持patch周围的局部连续性
patch尺寸K、步长S、填充尺寸P,在网络中设置参了2套参数:K = 7, S = 4, P = 3 ;K = 3, S = 2, P = 1
1 | class OverlapPatchEmbed(nn.Layer): |
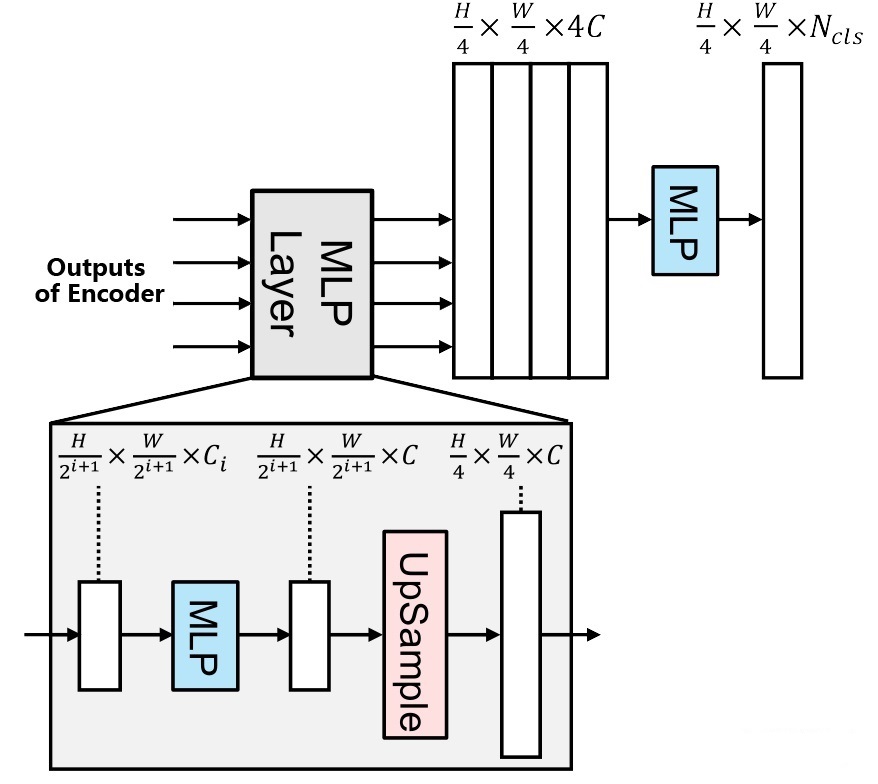
解码器
Lightweight All-MLP Decoder:在解码器部分,SegFormer采用了简单的结构,仅由MLP组成

有效感受野分析

如图3的放大图所示,MLP头部(蓝框)的ERF与阶段4(红框)不同,除了非局部注意外,局部注意明显更强。
在上采样阶段,Head的感受野除了具有非局部关注外,还有较强的局部关注。
作者认为之所以这种简单的Decoder能够很好地工作,关键在于分层的Transformer Encoder比传统的基于CNN的Encoder具有更大的感受野。
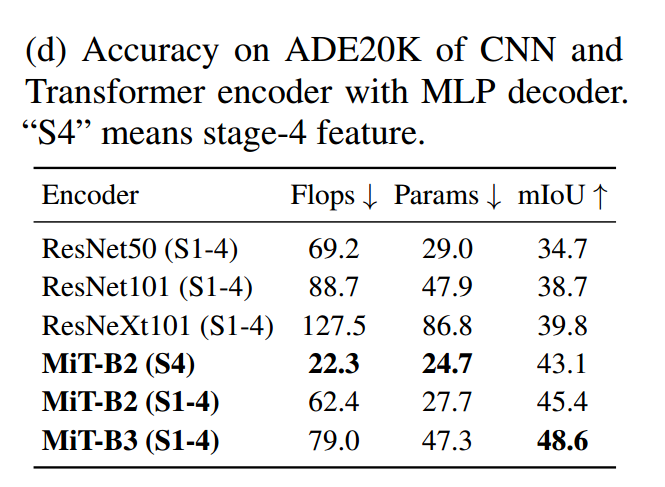
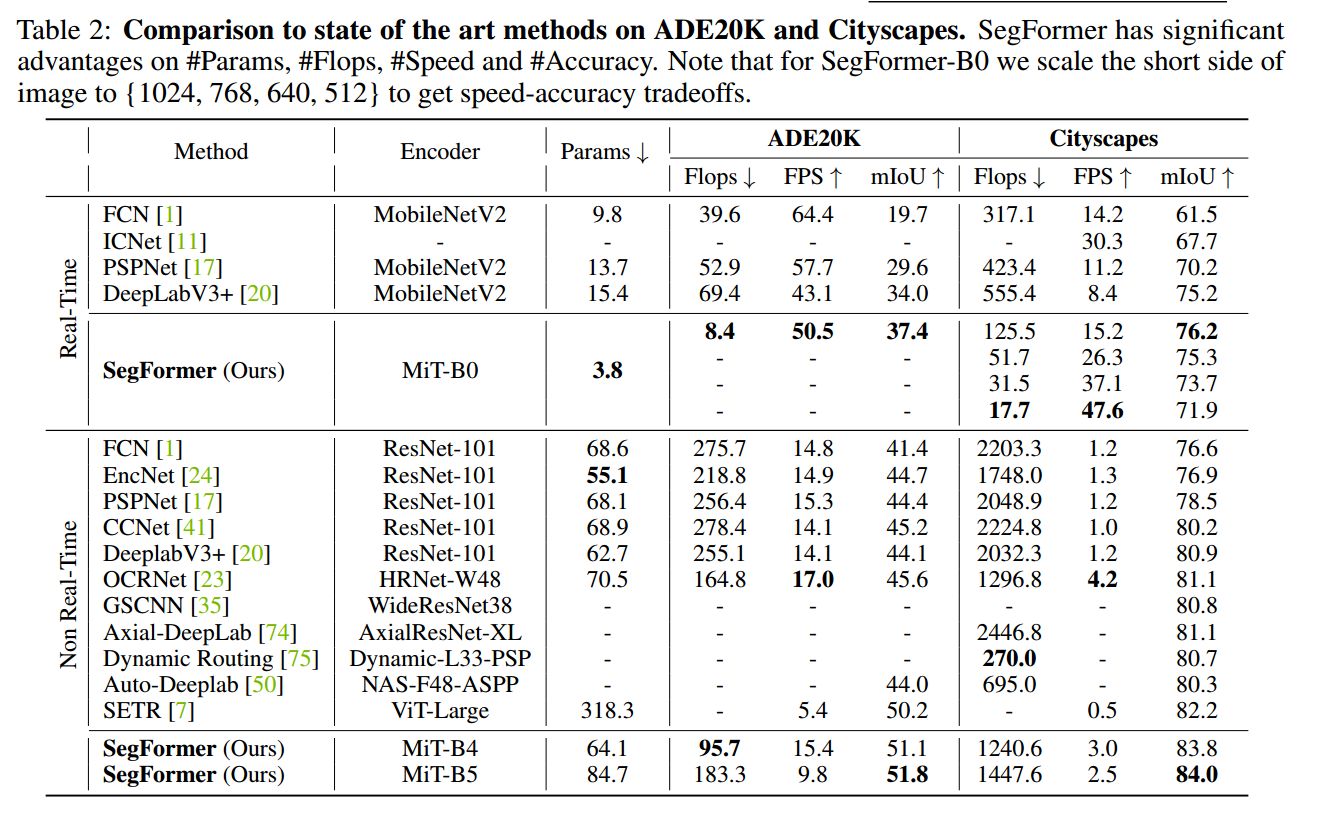
2.实验结果