
UNeXt
UNeXt
1.网络设计
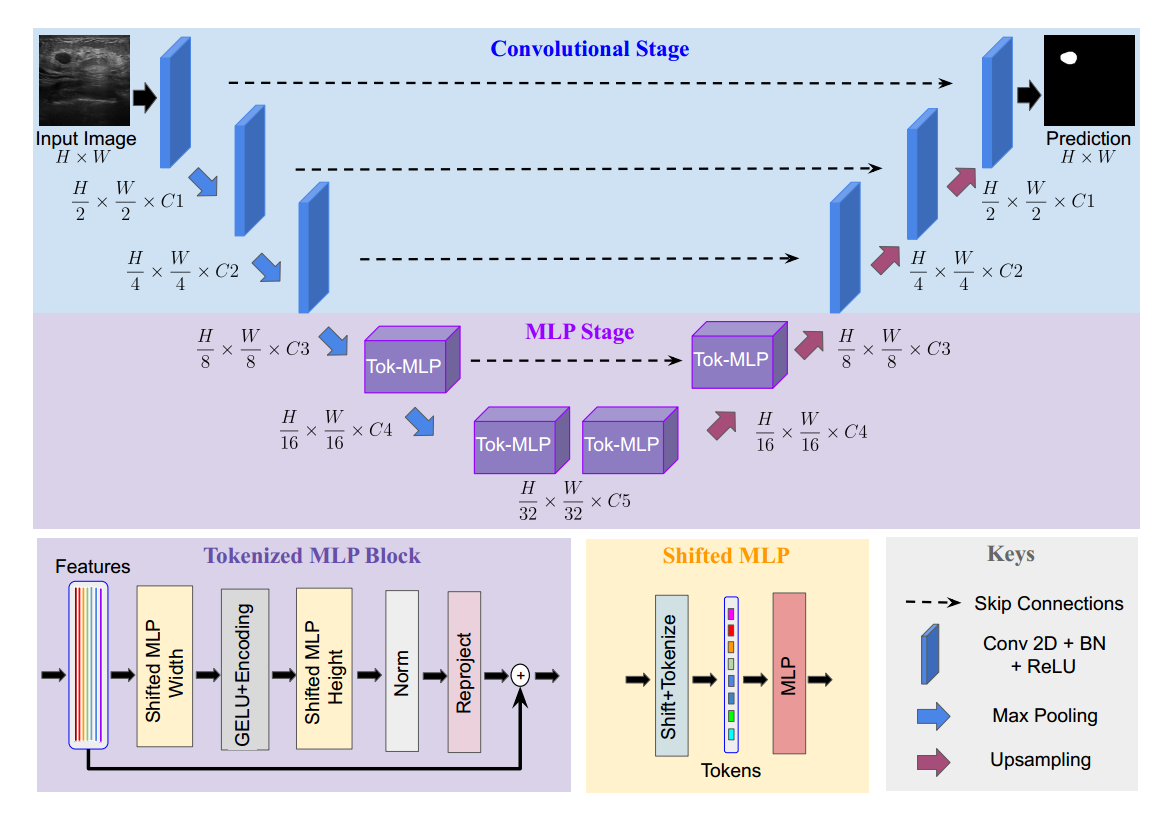
分成卷积阶段、标记化MLP阶段
编码器:进行两倍的下采样(2×2的最大池化层)
解码器:进行两倍的上采样(双线性插值),使用双线性插值而不是转置卷积,因为转置卷积基本上是可学习的上采样,会增加更多可学习参数。
C为超参数,一般取C1=32、C2=64、C3=128、C4=160、C5=256(C的取值比UNet小,减少了参数和计算)
注:充分考虑了模型维度对参数量和计算量的影响,采用了更少的参数设计
卷积阶段:每个卷积块配备了一个卷积层、一个批量归一化层和ReLU激活函数,使用3×3的卷积核大小,步幅为1,填充为1,用于保持特征图的空间分辨率不变,同时允许网络学习提取不同位置的特征信息。
Tokenized MLP Stage:

Conv:kernel_size=3,stride=2,padding=1,同时输出通道数(E)大于输入通道数(E为超参数,token数量),把特征图大小缩小了一半,增加了通道数
Shifted MLP:让模型更加关注 local 的信息
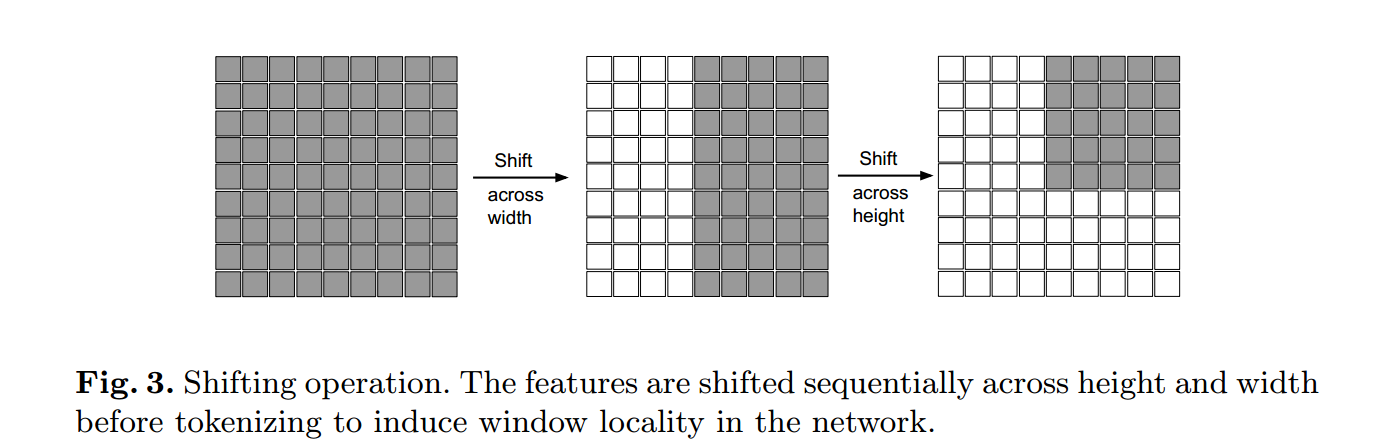
先使用0填充特征图,填充过后在通道维度做切割,再做平移操作,然后将各个切片合并在一起,最后提取特征图中间部分
1 | xn = x.transpose(1, 2).view(B, C, H, W).contiguous() |
DWConv:编码MLP特征的位置信息、减少运算量的作用
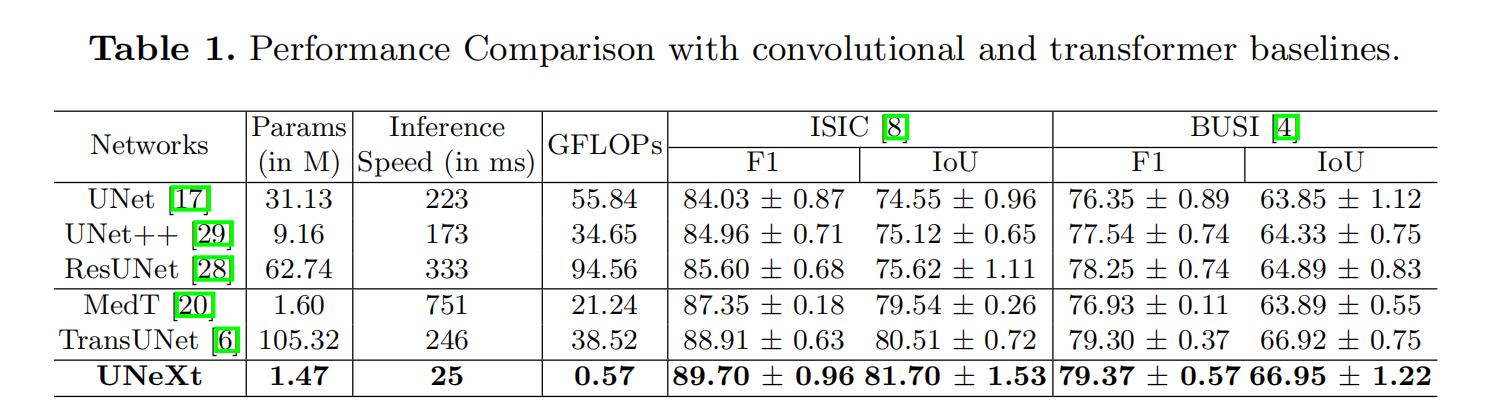
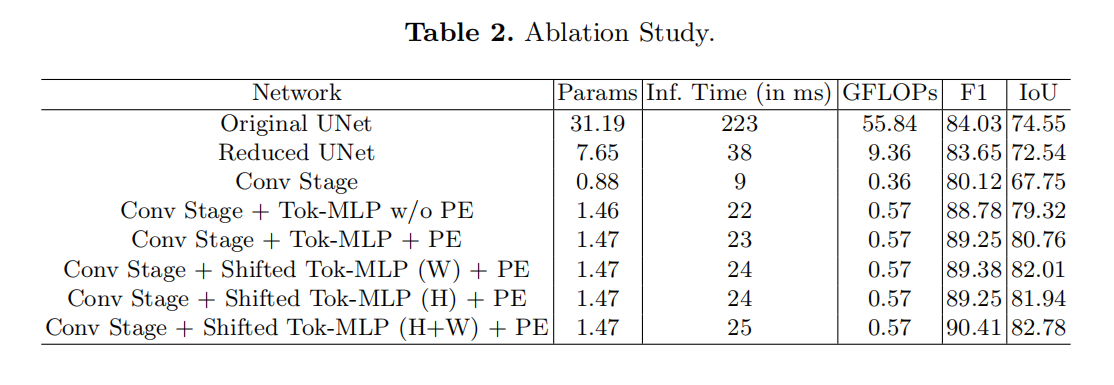
2.实验结果及消融实验
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 丹青两幻!
相关推荐



评论

