
SegFormer3D
SegFormer3D
论文:《SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation》(arXiv 2024)
作者提出了SegFormer3D使用全mlp解码器来聚合局部和全局注意力特征,来产生高度准确的分割掩码
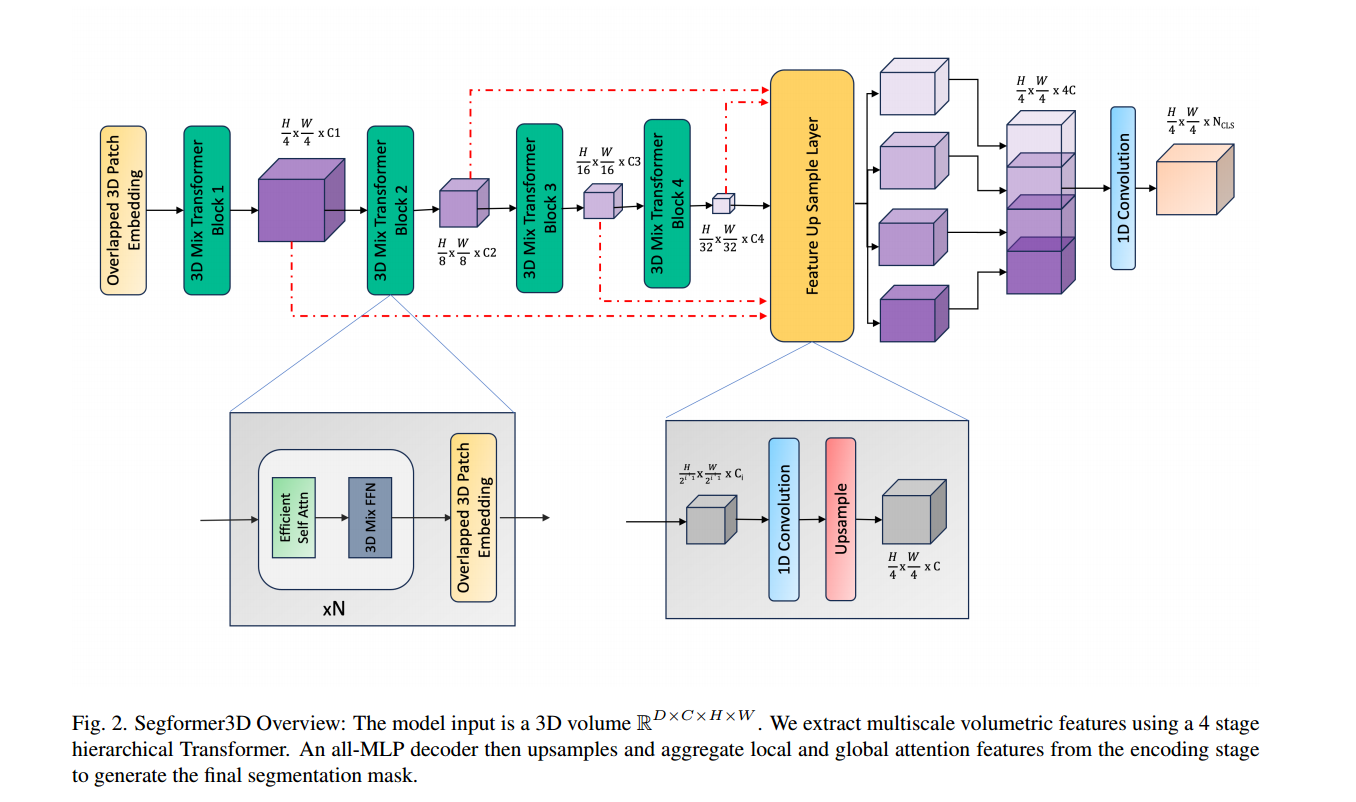
对于编码器部分:
使用patch merging进行下采样:与池化操作相比克服了像素生成过程中的邻域信息丢失的问题,同时也能节省一定的运算量
使用efficient self-attention:捕获全局信息的同时,用缩放系数R减少了self-attention计算的时间复杂度

舍弃了固定的位置编码,使用mix ffn模块来提取位置信息:
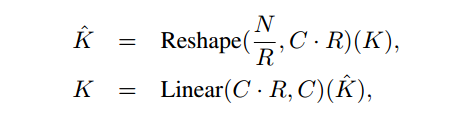
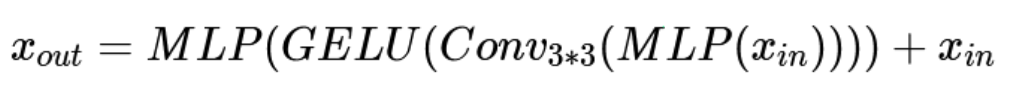
对于解码器部分:使用了全MLP的结构,使用了一个统一的模块完成了对不同尺度的特征的解码过程,简化了解码过程,确保在各种数据集中对体积特征进行高效且一致的解码,避免了过度参数化。
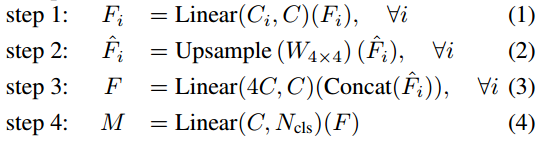
参数量和性能的比较:
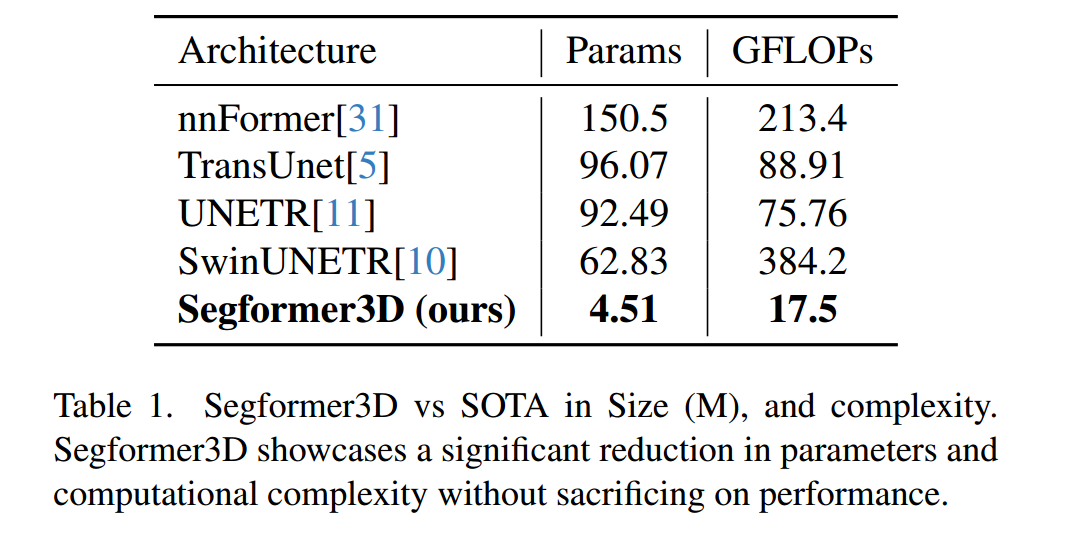
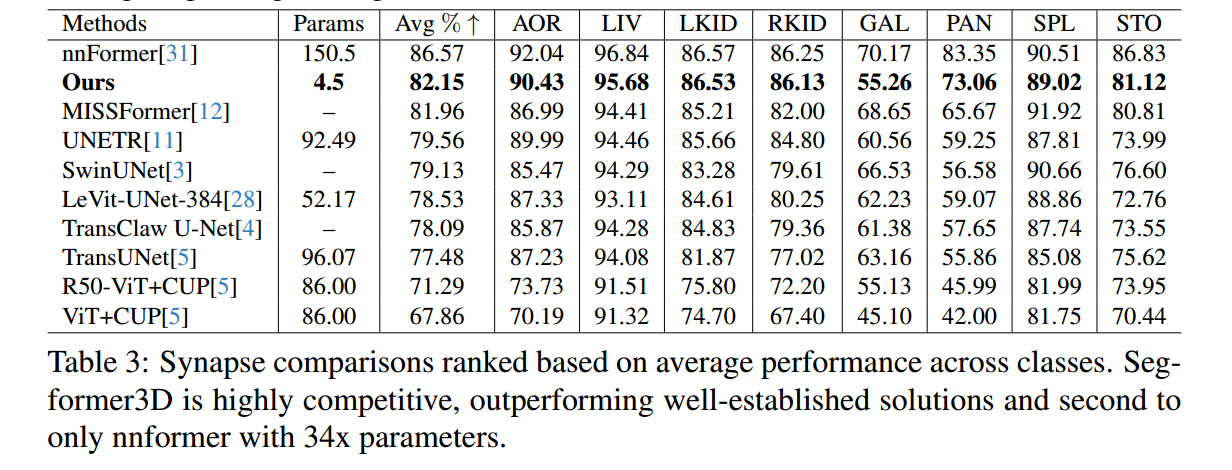
作者在编码器和解码器的设计中,都使用轻量化的操作(编码器部分的patch merging、efficient self-attention和解码器使用全mlp解码器来聚合局部和全局注意力特征),模型参数量和计算量都有明显的下降,但性能表现不如nnformer
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 丹青两幻!
相关推荐




评论
