
C++八股3
1.什么是大小端存储?
大端存储:数据的最高有效字节存放在内存地址的最低位置
小端存储:最低有效字节被存放在内存地址的最低位置
注:在网络协议中通常使用大端序
2.volatile、mutable和explicit关键字的用法
- volatile:
volatile关键字用于告诉编译器,该变量的值可能会在程序控制之外被改变(如硬件中断、操作系统、其他线程等)。因此,编译器不应该对涉及该变量的操作进行优化。
每次访问volatile变量时,都会从内存重新读取数据,而不是使用寄存器中的缓存副本。(这样可以防止变量被其他线程修改后读到错误的变量值)
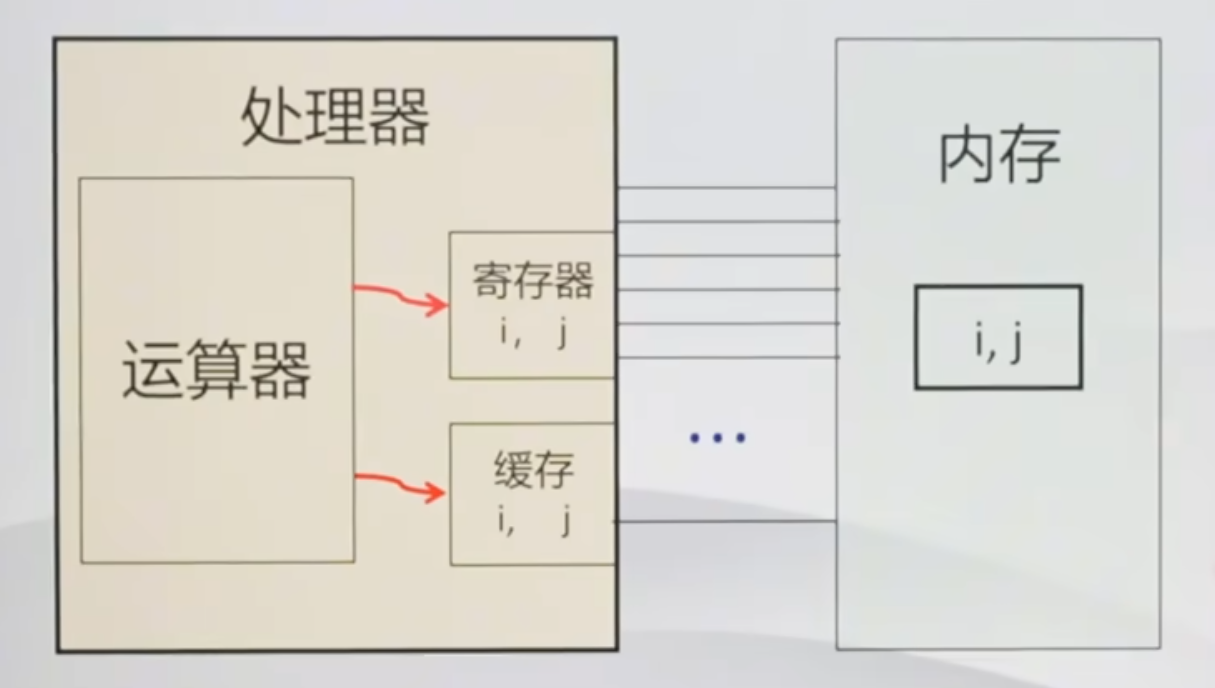
注:现代编译器为了提高性能,通常会将经常访问的变量值保存在CPU寄存器中,以便快速访问。
- mutable:
mutable关键字用于允许对象的某些成员变量即使在const成员函数内也可以被修改。
1 |
|
- explicit:
explicit关键字用于防止单参数构造函数的隐式类型转换。只能应用于类内部的构造函数声明。
1 | class Integer { |
3.什么情况下会调用拷贝构造函数
对象初始化: 用类的一个实例化对象去初始化另一个对象的时候
按值传递参数: 当一个函数的参数是类的对象且通过值传递(非引用传递),在函数调用时会创建一个参数的副本,此时会调用拷贝构造函数。
1
2void useClassA(A a) {} // 函数定义
useClassA(a1); // 调用时会调用拷贝构造函数
4.C++中有几种类型的new
- Plain New
Plain new指的是标准的、普通的new操作符,用于动态分配内存。它不仅负责分配所需的内存空间,还会调用对象的构造函数(如果是对象的话)。
异常处理: 在C++中,当使用plain new进行内存分配且分配失败时(例如,系统无法提供请求的内存大小),它会抛出一个std::bad_alloc异常,而不是返回NULL。
1 |
|
nothrow new
nothrow new在空间分配失败的情况下是不抛出异常,而是返回NULL1
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
int main()
{
char *p = new(nothrow) char[10e11];
if (p == NULL)
{
cout << "alloc failed" << endl;
}
delete p;
return 0; }
//运⾏结果:alloc failedPlacement New
placement new允许在⼀块已经分配成功的内存上新构造对象或对象数组。placement new不用担心内存分配失败,因为它根本不分配内存,它做的唯⼀⼀件事情就是调⽤对象的构造函数。
用途: 主要用于优化性能和控制内存管理,例如在一个循环中反复创建和销毁对象时,可以避免频繁的内存分配和释放操作,从而提高效率。
注1:显式调用析构函数:由于 placement new 只负责调用对象的构造函数,并不负责释放内存,因此当你不再需要对象时,必须手动调用对象的析构函数来清理资源。
注2:不要使用 delete:不能对通过 placement new 创建的对象直接使用 delete,因为这可能导致内存泄漏或其他运行时错误。应该首先显式调用对象的析构函数,然后根据情况决定是否释放底层内存。(因为 delete 预期的是由 new 返回的一个指针,它只知道如何释放这块特定类型的内存。)
1 |
|
5.C++的异常处理的方法
try、throw和catch关键字
try:
try块用于包裹可能抛出异常的代码段。当try块中的任何代码抛出了一个异常,程序会立即寻找与之匹配的catch块进行处理。throw: 当程序检测到一个无法处理的错误时,可以使用
throw语句抛出一个异常。这个异常可以是任意类型的数据(例如整数、浮点数、字符串或者自定义类对象),它包含了关于错误的信息。catch:
catch块用于捕获由throw语句抛出的异常。每个catch后面都跟着一个参数列表,指定了它可以处理的异常类型。一旦某个异常被抛出,程序会查找最近的匹配catch块,并将控制权转移到该块。如果找不到匹配的catch块,程序将终止运行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19double m = 1, n = 0;
try {
cout << "before dividing." << endl;
if (n == 0)
throw -1; // 抛出int型异常
else if (m == 0)
throw -1.0; // 抛出 double 型异常
else
cout << m / n << endl;
cout << "after dividing." << endl;
}
catch (double d) {
cout << "catch (double)" << d << endl;
}
//通用的catch(...)块
catch (...) {
cout << "catch (...)" << endl;
}
cout << "finished" << endl;
函数的异常声明列表: 在定义函数的时候知道函数可能发⽣的异常,可以在函数声明和定义时,指出所能抛出异常的列表.
int fun() throw(int,double,A,B,C){...};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
// 定义三个可能被抛出的异常类
class ExceptionA {};
class ExceptionB {};
class ExceptionC {};
// 函数fun声明和定义时指定了它可能抛出的异常类型:int, double, ExceptionA, ExceptionB, ExceptionC
int fun() throw(int, double, ExceptionA, ExceptionB, ExceptionC) {
int condition = 3; // 假设根据某种条件决定抛出何种异常
if (condition == 1)
throw 1; // 抛出int型异常
else if (condition == 2)
throw 2.0; // 抛出double型异常
else if (condition == 3)
throw ExceptionA(); // 抛出自定义异常ExceptionA
else if (condition == 4)
throw ExceptionB(); // 抛出自定义异常ExceptionB
else if (condition == 5)
throw ExceptionC(); // 抛出自定义异常ExceptionC
return 0;
}
int main() {
try {
fun();
}
catch (int e) {
std::cout << "Caught an int exception: " << e << std::endl;
}
catch (double e) {
std::cout << "Caught a double exception: " << e << std::endl;
}
catch (ExceptionA& e) {
std::cout << "Caught an ExceptionA" << std::endl;
}
catch (ExceptionB& e) {
std::cout << "Caught an ExceptionB" << std::endl;
}
catch (ExceptionC& e) {
std::cout << "Caught an ExceptionC" << std::endl;
}
catch (...) { // 捕获所有其他未列出的异常
std::cout << "Caught an unspecified exception" << std::endl;
}
return 0;
}C++标准异常类exception
C++ 标准库中有⼀些类代表异常,这些类都是从 exception 类派⽣⽽来的
std::bad_typeid:当使用typeid运算符对一个多态类的指针进行操作时,如果该指针的值为NULL(即指向空),则会抛出std::bad_typeid异常。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class A {
public:
virtual ~A() {}
};
int main() {
A* ptr = nullptr;
try {
std::cout << typeid(*ptr).name() << std::endl; // 这里会抛出 std::bad_typeid 异常
} catch (const std::bad_typeid& e) {
std::cerr << "Caught std::bad_typeid: " << e.what() << std::endl;
}
return 0;
}std::bad_cast:当使用dynamic_cast进行从多态基类对象(或引用)到派生类的引用的强制类型转换时,如果转换是不安全的(例如,基类指针实际上并不指向正确的派生类对象),则会抛出std::bad_cast异常。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Base { public: virtual ~Base() {} };
class Derived : public Base {};
int main() {
Base* basePtr = new Base();
try {
Derived& derivedRef = dynamic_cast<Derived&>(*basePtr); // 这里会抛出 std::bad_cast 异常
} catch (const std::bad_cast& e) {
std::cerr << "Caught std::bad_cast: " << e.what() << std::endl;
}
delete basePtr;
return 0;
}std::bad_alloc: 当使用new运算符进行动态内存分配时,如果没有足够的内存,则会引发std::bad_alloc异常。std::out_of_range: 当你使用vector或string的at()成员函数根据下标访问元素时,如果提供的下标越界了,则会抛出std::out_of_range异常。
6.形参与实参的区别?
- 形参变量的作用范围:形参是在定义函数时声明的变量,它们只有在函数被调用时才会分配内存单元,并且仅在函数内部有效。
- 实参的类型与值确定性:这就要求在调用函数之前,确保所有实参都有明确的值。
- 实参与形参的一致性:实参和形参的数量、类型以及顺序需要严格匹配。
- 非指针类型的形参与实参的独立性:如果形参和实参都不是指针类型,那么在函数执行期间,形参会创建实参的一个副本,即形参获得的是实参值的一份拷贝。这样,在函数内部对形参所做的任何改变都不会影响到外部的实参。当函数执行完毕后,形参占用的内存被释放,而实参保持不变。
7.值传递、指针传递、引用传递的区别和效率
- 值传递:将实际参数的值复制一份传递给函数的形式参数。函数内部对形参的修改不会影响到实参。如果值传递的对象是类对象 或是大的结构体对象,将耗费一定的时间和空间。实参和形参在不同的内存位置,它们占用不同的存储空间。形参是实参的一个副本,当函数调用结束后,形参占用的内存空间会被释放。
- 指针传递:函数参数为指针类型。通过传递变量的地址,函数内部可以通过这个地址访问和修改原始变量的值。(传值,传递的是固定为4字节的地址值)
- 引用传递:在函数调用时,将实际参数的引用(别名)传递给函数的形式参数。对形参的操作实际上就是对实参的操作。(传地址)
效率上,指针传递和引用传递比值传递效率高。
注:需要返回多个值时可以使用指针作为参数:当一个函数需要返回多个值时,可以使用指针作为参数来允许函数修改传入的变量。
1 | void divide(int dividend, int divisor, int* quotient, int* remainder) { |
8.局部变量什么时候初始化
普通局部变量:
- 初始化时机:普通局部变量在每次进入其作用域时被创建,并且可以在声明时或者之后进行初始化。初始化不是自动的,需要显式地给它们赋值。
静态局部变量:
- 初始化时机:在首次用到时初始化,可使用变量初始化,这是因为初始化要执行构造函数
- 析构顺序:当程序结束时,静态局部变量会按照它们构造的逆序进行析构。此外,C++通过
atexit()函数来管理这些对象的析构顺序,确保它们能以正确的顺序被销毁。
全局静态变量:
- 初始化时机:全局静态变量和静态局部变量类似,在程序开始执行前就已初始化。然而,在不同编译单元中的全局静态对象的初始化顺序是不确定的,这可能导致依赖于特定初始化顺序的问题。
- 解决方法:一种常用的解决方案是使用单例模式中的静态局部变量。由于静态局部变量具有“延迟初始化”的特点,即只有在首次使用时才会初始化,因此可以用来控制初始化顺序,避免跨编译单元初始化顺序导致的问题。
9.深拷贝与浅拷贝
- 浅拷贝:浅拷贝是指简单地将原对象的基本数据类型的值复制给新对象,并且对于引用类型的数据(如指针),只是复制了指向实际数据的引用(即内存地址),并没有为引用类型的数据开辟新的内存空间。
- 深拷贝:深拷贝不仅复制了基本数据类型的值,而且对于引用类型的成员变量,还会在堆上为其指向的数据分配新的内存空间,并将这些数据复制到新的内存位置,从而使得新对象拥有自己的独立数据副本。
10.new、delete p、delete [] p、allocator都有什么作用?
new[]创建动态数组:当使用new分配一个数组时,方括号[]内的值必须是整数类型,它可以是变量(即运行时确定的值),而不必是常量表达式。1
2int size = 5;
int* arr = new int[size]; // 合法,size可以是变量new返回元素类型的指针: 当使用new[]来动态创建数组时,返回的是指向数组第一个元素的指针,而不是一个数组类型的对象。1
2int* arrayPtr = new int[10];
// arrayPtr 是一个 int 类型的指针delete[]销毁顺序: 使用delete[]删除通过new[]分配的数组时,数组中的对象会按照它们被构造的逆序进行析构。因为C++保证了对象的析构顺序与它们的构造顺序相反,以确保资源正确释放。new/deletevsallocatornew/delete局限性:将构造函数/析构函数与内存管理绑定在一起不够灵活std::allocator(分配器)的作用:std::allocator是C++标准库提供的一个工具,用于分离内存分配和对象构造的过程。它允许程序员先申请一块未初始化的内存,然后根据需要手动构造对象。这种方式提供了更大的灵活性,比如延迟对象的初始化时间或者复用已分配的内存块,从而可能提高性能或减少内存碎片。1
2
3
4
5
6
std::allocator<int> alloc; // 创建一个 allocator 对象
int* p = alloc.allocate(10); // 分配内存但不初始化
alloc.construct(p, 100); // 初始化某个位置的对象
alloc.deallocate(p, 10); // 释放内存
11.new和delete的实现原理, delete是如何知道释放内存的大小的额?
对于数组,new[]会额外存储数组的大小,delete[]会根据这个大小正确地调用析构函数并释放内存。
12.malloc与free的实现原理?
alloc 和 free 的底层实现依赖于操作系统提供的系统调用,主要包括:
brk:通过调整堆的边界来分配内存。mmap:在进程的虚拟地址空间中映射一块内存区域。munmap:释放由mmap分配的内存。
内存分配的两种方式:
brk系统调用(小于 128KB):调整堆的边界(即数据段的最高地址指针_edata)来分配内存; 分配的内存是连续的,释放时需要从高地址向低地址依次释放。brk将_edata指针向高地址方向移动,扩展堆的大小。- 分配的内存是虚拟内存,物理内存并未立即分配。
- 当程序首次访问这块内存时,操作系统会触发缺页中断,分配物理内存并建立虚拟内存与物理内存的映射关系。
mmap系统调用(大于 128KB):mmap在进程的虚拟地址空间中(堆和栈之间的文件映射区域)找一块空闲的虚拟内存。; 分配的内存可以单独释放,灵活性更高。mmap在文件映射区域中分配一块虚拟内存。- 同样,物理内存并未立即分配,而是在首次访问时通过缺页中断分配。
内存紧缩(trim):
- 当
free释放内存后,如果堆顶的空闲内存超过一定阈值(默认 128KB,可通过M_TRIM_THRESHOLD调节),操作系统会执行内存紧缩操作(trim)。 - 内存紧缩会将空闲的内存归还给操作系统,减少进程的内存占用。
- 当
malloc 的具体实现机制:
空闲内存链表:
- 操作系统中维护一个记录空闲内存地址的链表。
- 当程序调用
malloc时,操作系统会遍历这个链表,寻找第一个大小满足需求的空闲内存块。 - 如果找到合适的内存块,则将其从空闲链表中删除,并分配给程序。
- 如果没有找到合适的内存块,则会通过
brk或mmap系统调用向操作系统申请更多的内存。
内存分配算法:
malloc通常使用一些内存分配算法(如首次适应、最佳适应或伙伴系统)来管理空闲内存链表,以提高内存分配的效率。
free 的具体实现机制:
- 释放内存:
- 当程序调用
free时,操作系统会将释放的内存块重新加入到空闲内存链表中。 - 如果释放的内存是通过
brk分配的,且位于堆的顶部,则可能会触发内存紧缩操作,将空闲内存归还给操作系统。 - 如果释放的内存是通过
mmap分配的,则直接调用munmap系统调用将内存归还给操作系统。
- 当程序调用
13.内联函数和普通函数的区别
执行效率:内联函数效率高
- 内联函数:当一个函数被声明为内联函数时,编译器会在每次调用该函数的地方将其代码展开,而不是进行常规的函数调用(如保存当前环境、跳转到函数入口地址执行等)。这样做可以减少函数调用带来的开销,特别是对于简单的、短小的函数来说,能提高程序运行效率。
- 普通函数:普通函数调用涉及到栈帧的创建与销毁、参数传递、返回值处理等一系列操作,这些都会带来一定的性能开销。
代码大小:内联函数会增大代码量
- 内联函数:由于内联函数是将函数体直接插入到调用点,如果一个内联函数在一个程序中被多次调用,那么这个函数的代码就会被复制多份,这可能导致生成的可执行文件变大。
- 普通函数:普通函数只有一份副本,无论它被调用多少次,都不会增加代码量。





