
Protobuf
Protobuf
Protobuf序列化的步骤
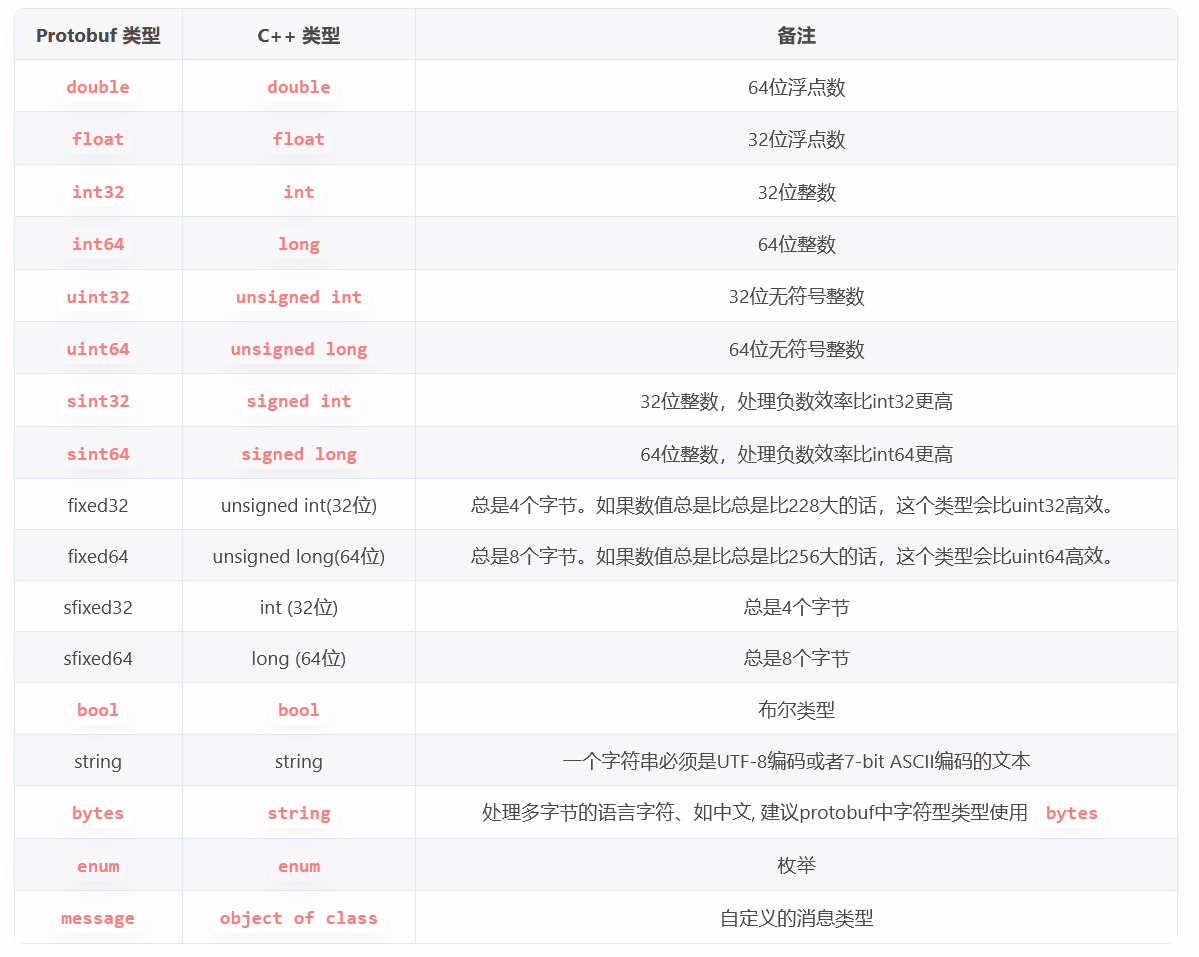
protobuf中的数据类型 和 C++ 数据类型对照:
使用protobuf进行序列化的步骤:
- 定义.proto文件:
.proto文件来描述要序列化的数据结构
1 | //声明所使用的protobuf版本号 |
注:等号后面的编号要从1开始,每个成员都有一个唯一的编号,不能重复,一般连续编号即可。
- 编译.proto文件:使用
protoc编译器将user_info.proto文件编译成C++代码
1 | protoc -I path <user_info.proto> --cpp_out=输出路径(存储生成的c++文件) |
注1:-I: 参数后面可以跟随一个或多个路径,用于告诉编译器在哪些路径下查找导入的文件或依赖的文件,如protoc -I path1 -I path2 或 protoc -I path1:path2
注2:这会在输出路径下生成user_info.pb.h和user_info.pb.cc两个文件。
- 在C++项目中集成:
在项目的源文件中包含生成的头文件:#include "user_info.pb.h"
序列化和反序列化:
序列化:创建一个
UserInfo对象并设置其字段值,然后调用SerializeToArray或SerializeToString方法将其序列化为字节流。1
2
3
4
5
6
7
8UserInfo user;
user.set_id(1);
user.set_name("John Doe");
user.set_email("johndoe@example.com");
std::string data;
//接受一个std::string类型的引用作为输出参数
user.SerializeToString(&data);反序列化:创建一个
UserInfo对象,并通过调用ParseFromArray或ParseFromString方法从字节流中恢复数据。1
2
3
4
5
6
7
8
9UserInfo user;
if (user.ParseFromString(data)) {
// 成功解析后,可以访问user的字段了
std::cout << "ID: " << user.id() << std::endl;
std::cout << "Name: " << user.name() << std::endl;
std::cout << "Email: " << user.email() << std::endl;
} else {
// 解析失败
}
repeated 限定修饰符
repeated: 用于定义可重复字段的关键字,与数组或列表概念相似。
eg:
- 定义 .proto 文件:
1 | syntax = "proto3"; |
- 使用生成的类:
1 |
|
枚举
c++中的枚举类型:
1 | enum Color |
.proto 文件中:
1 | enum Color |
注:第一个元素的元素值必须为0,元素之间使用;
Protobuf中包的概念
Protobuf使用包的概念避免消息类型之间的命名冲突
eg:
定义 .proto 文件:
user_info.proto:
1
2
3
4
5
6
7
8
9syntax = "proto3";
package user.profile;
message UserInfo {
string name = 1;
int32 id = 2;
string email = 3;
}order_info.proto:
1
2
3
4
5
6
7
8
9syntax = "proto3";
package order.details;
message OrderInfo {
string product_name = 1;
int32 order_id = 2;
string customer_email = 3;
}
在C++中使用:
1 |
|
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 丹青两幻!
相关推荐





评论
