
面试模板
1.自我介绍
尊敬的面试官,您好。我是东北大学在读硕士研究生XXX。我的技术栈是C++,熟悉windows和linux的C++开发,熟悉网络编程开发和常见的网络协议。
在实践过程中,我实现过一个高性能RPC框架,让我对分布式系统通信和RPC远程过程调用有了进一步的认识,另外,我也做Linux性能监控项目,基于grpc实现了对服务器上的性能数据采集,并进行监控的过程。
在校期间,我曾多次获得过校奖学金,参加过蓝桥杯和程序设计天梯赛,并均获得了国家三等奖,这些经历使我具有扎实的算法基础和工程实践能力,所以我认为贵公司的开发岗位要求和我的技术能力是非常契合的。
最后,非常感谢您给我这次面试机会,谢谢。
2.1 介绍一下你的项目(分布式Linux性能监控)
在校期间我做过分布式Linux性能监控的项目,首先,我利用了Docker容器化的技术,通过Dockerfile来构建环境,例如安装CMake、gRpc、Protobuf等依赖,以此来简化多服务器的部署。
通过基于gRpc的框架来构建服务端和客户端,服务端位于目标监控的服务器上,客户端调用monitor模块和display模块实现对服务端的监控,通过这样的设计保证了模块之间的低耦合。
对于monitor模块主要作用是用来获取服务器端的CPU、内存、网络、软中断等性能指标。Display模块就利用了monitor模块所获取到的性能指标来使用Qt构建ui界面。
最后,使用stress工具模拟高负载情况,验证了系统的稳定性。
遇到的困难:
- protobuf如何使用cmake进行编译
2.2 介绍一下你的项目(RPC)
这个项目是基于C++实现的RPC网络通信框架,实现了同一台机器不同进程间或者不同机器间的服务调用。
首先,本项目是使用protobuf进行序列化和反序列化,并使用了Zookeeper作为服务注册中心,动态地存储服务的ip和端口。
其次,对于网络层采用Muduo库的Reactor模型,来将网络IO和业务逻辑相解耦,提升系统的并发处理能力。
最后,通过CMake构建编译环境。
1.Docker相关
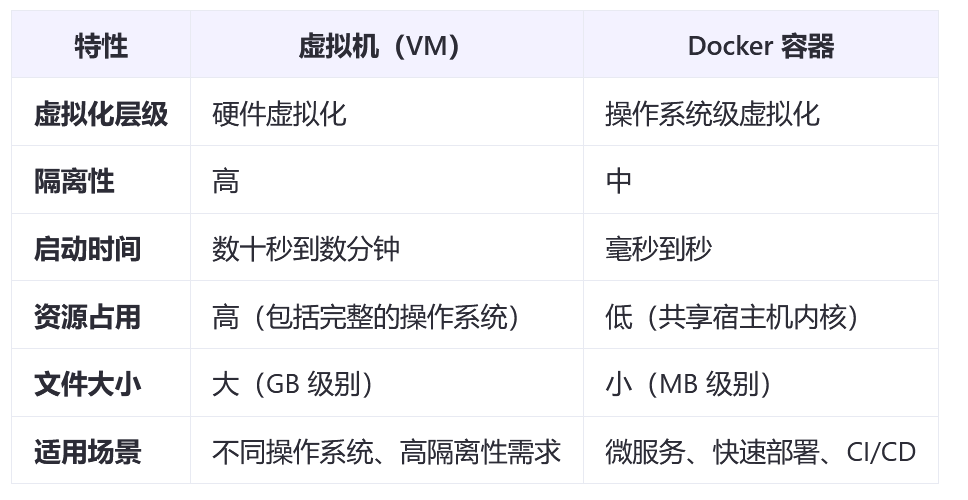
1.1 docker和VM的区别
Docker 和虚拟机是两种不同的虚拟化技术,它们的核心目标都是为了实现资源隔离和环境一致性。
性能开销:
- 每个虚拟机都需要运行一个完整的操作系统,所以资源消耗较大,启动时间较长,占用更多的磁盘空间和内存。
- 容器共享宿主机的内核,因此几乎没有额外的虚拟化开销,启动速度更快(通常在毫秒级别),并且占用的磁盘空间和内存也更少。
隔离性:
- 虚拟机提供了更强的隔离性,因为每个虚拟机都运行在一个完全独立的操作系统中,彼此之间互不影响。这种隔离性使得虚拟机更适合需要高度安全性和稳定性的场景。
- 容器之间的隔离性相对较弱,因为它们共享宿主机的内核。如果某个容器被攻破,可能会对宿主机或其他容器造成影响。不过,通过命名空间和控制组等技术,Docker 已经能够提供一定程度的安全隔离。Docker容器适合需要进行快速部署的场景。
1.2 使用docker创建镜像的流程是什么?相关的命令有哪些?
编写 Dockerfile(.dockerfile文件)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46FROM ubuntu:18.04
ARG DEBIAN_FRONTEND=noninteractive
ENV TZ=Asia/Shanghai
SHELL ["/bin/bash", "-c"]
RUN apt-get clean && \
apt-get autoclean
COPY apt/sources.list /etc/apt/
RUN apt-get update && apt-get upgrade -y && \
apt-get install -y \
htop \
apt-utils \
curl \
git \
openssh-server \
build-essential \
qtbase5-dev \
qtchooser \
qt5-qmake \
qtbase5-dev-tools \
libboost-all-dev \
net-tools \
vim \
stress
RUN apt-get install -y libc-ares-dev libssl-dev gcc g++ make
RUN apt-get install -y \
libx11-xcb1 \
libfreetype6 \
libdbus-1-3 \
libfontconfig1 \
libxkbcommon0 \
libxkbcommon-x11-0
# 复制当前目录下的文件到容器中
COPY install/cmake /tmp/install/cmake
# 安装 cmake 依赖
RUN /tmp/install/cmake/install_cmake.sh
COPY install/protobuf /tmp/install/protobuf
RUN /tmp/install/protobuf/install_protobuf.sh
COPY install/abseil /tmp/install/abseil
RUN /tmp/install/abseil/install_abseil.sh
COPY install/grpc /tmp/install/grpc
RUN /tmp/install/grpc/install_grpc.sh
RUN apt-get install -y python3-pip
RUN pip3 install cuteci -i https://mirrors.aliyun.com/pypi/simple
COPY install/qt /tmp/install/qt
RUN /tmp/install/qt/install_qt.sh构建镜像:使用
docker build命令根据Dockerfile构建镜像。测试镜像:
docker images查看本地已经存在的镜像列表运行容器:
docker run运行镜像并启动容器。查看运行中的容器:
docker ps进入容器的交互式终端:
docker exec -it <容器ID或名称> /bin/bash
1.3 docker的namespace是什么?有什么作用?
namespace是实现隔离的机制,每个容器运行在一个独立的命名空间之中
每个进程都有自己所属的 namespace,可以在 /proc/<pid>/ns/ 目录下查看。
Docker 使用的主要几种 namespace:
- PID Namespace:用于隔离进程ID编号空间。这意味着在不同的 PID namespace 中可以存在相同的 PID,而且一个 namespace 中的进程对于另一个 namespace 来说是不可见的。
- Network Namespace:提供独立的网络协议栈(例如网络设备、IP地址、路由表等)。每个 Network namespace 都有自己的网络配置和状态。
- Mount Namespace:允许修改文件系统的挂载点列表,使不同容器可以看到完全不同的文件系统结构。
- UTS Namespace:允许单个系统上存在不同的主机名和域名,这有助于创建更真实的测试环境。
- IPC Namespace:用于隔离System V IPC 和 POSIX消息队列,这样即使在同一系统上,不同容器也可以安全地使用这些通信机制而不会相互干扰。
- User Namespace:提供了用户ID和组ID的隔离,使得同一用户的ID在不同的namespace中可以对应不同的权限。
通过使用这些 namespace,Docker 能够为每个容器创建一个独立的执行环境,这个环境看起来就像是一个单独的操作系统实例。这种隔离性是容器技术的核心特点之一,使得多个容器可以在同一台机器上共存而互不干扰。同时,由于它们共享同一个内核,所以比传统的虚拟机更加高效且占用资源更少。
1.4 docker的cgroups是什么?有什么作用?
cgroups是一种用于限制和隔离一个或一组进程对系统资源使用的机制,将一组进程组织在一个控制组中,为这个控制组分配特定的资源限制与优先级,包括 CPU资源、内存、网络等。确保容器在共享主机上合理利用系统资源,避免资源竞争和过度使用。
容器利用 Linux 的namespace技术来实现这种隔离,并结合 cgroups 来管理资源的使用,保证容器之间不会互相干扰。
1.5 什么是镜像?为什么要使用镜像?
镜像:包含程序运行环境的软件包
使用 Docker镜像 的主要原因:
- 环境一致性: 确保在任何地方运行结果一致。
- 快速部署: 镜像可以 一键运行,秒级启动容器
- 资源隔离: 每个容器基于镜像独立运行,资源相互隔离。
1.6 docker分层原理与内部结构
Docker采用分层存储结构:
- 基础镜像层:通常是一个最小化的操作系统环境,例如
alpine或ubuntu。它是其他所有层的基础。 中间层:基于基础镜像层之上,每执行一条指令(比如
RUN命令),都会创建一个新的层。这包括安装软件包、复制文件等操作。可写层(容器层):当使用
docker run命令启动一个容器时,在镜像的最顶层会添加一个可写的容器层。所有对容器的更改(如文件的增删改)都只会发生在这一层,而不会影响到下面的只读层。容器删除后,可写层也随之消失(除非数据被持久化)。
分层的工作方式:
镜像构建时的分层:只读层(镜像层)
1
2
3
4
5FROM ubuntu:20.04 # 基础层(第1层)
RUN apt-get update # 第2层
RUN apt-get install -y nginx # 第3层
COPY index.html /var/www/html/ # 第4层
CMD ["nginx", "-g", "daemon off;"] # 第5层容器运行时的分层: 可写层(容器层) 通过
docker run创建
分层的好处:
- 高效的存储:由于各层之间共享(只读层共享,可写层独立),如果两个镜像共用了某些层,那么这些层只需要存储一次,从而节省了磁盘空间。
- 快速部署:在构建新镜像时,只有变动的部分需要重新生成新的层,其余未变的部分可以直接复用,大大加快了镜像的构建速度。
2.Protobuf
Protobuf: 轻量级的数据序列化协议
2.1 为什么数据的传输和通信需要序列化?
跨平台兼容性:不同的系统、编程语言或者运行环境可能对数据结构有不同的表示方法。通过序列化,可以将这些差异抽象掉,使得数据可以在不同平台间进行有效传输。
优化传输大小:有效的序列化格式能够减少数据传输的体积,从而提高传输效率并节省带宽。
注:Protobuf 使用字段编号(如
1、2)来代替字段名,这样可以大大减少字段标识的占用空间。
2.2 为什么使用protobuf?
性能:Protobuf 使用二进制格式进行数据编码,这使得它更加紧凑,占用更少的空间,同时也加快了序列化和反序列化的速度。
注:字段编号(如
1、2)来代替字段名,另外,二进制格式相比于文本格式去掉了空白字符。支持跨平台:Protobuf 支持多种编程语言,如 C++, Java, Python 等,并且支持跨平台使用。
3.CMake
3.1 使用cmake进行编译的步骤?
编写
CMakeLists.txt文件1
2
3
4
5
6
7
8
9
10cmake_minimum_required(VERSION 3.10.2)
project(test_monitor LANGUAGES CXX)
set(CMAKE_MODULE_PATH "${CMAKE_SOURCE_DIR}/cmake")
set(CMAKE_CXX_STANDARD 17)
add_subdirectory(rpc_manager)
add_subdirectory(test_monitor)
add_subdirectory(proto)
add_subdirectory(display_monitor)创建构建目录:创建一个单独的构建目录build,避免污染源代码目录。
进入构建目录,执行
cmake ..,生成Makefile执行构建: 使用
make命令执行构建
3.2 cmake的常用API?
- 项目配置:
cmake_minimum_required(VERSION <version>) - 设置变量:
set(<variable> <value>) - 定义一个可执行目标:
add_executable(<target_name> <source_files>) - 定义一个库目标:
add_library(<target_name> [STATIC | SHARED | MODULE] <source_files>) - 链接库:
target_link_libraries(<target> <libraries>) - 指定头文件路径:
target_include_directories(<target> [PRIVATE | PUBLIC | INTERFACE] <directories>) - 将子目录添加到构建系统:
add_subdirectory
3.3 动态库和静态库的区别?
静态库:
- 编译时集成:静态库在编译阶段与应用程序代码一起被编译并链接到可执行文件中。这意味着每个使用该静态库的应用程序都会包含一份库代码的副本。
- 大小和性能:由于静态库的代码被直接嵌入到最终的可执行文件中,这可能导致生成的可执行文件较大。
动态库:
- 动态库在程序运行时才被加载到内存,并与程序进行链接。多个程序可以共享同一个动态库实例,从而节省内存和磁盘空间。
静态库适合于确保程序独立运行,减少对外部依赖的情况;动态库则有助于资源共享、减小程序体积,并简化库的升级流程。
4.gRPC
4.1 介绍一下gRPC
gRPC是一种高性能的远程过程调用框架,主要用于分布式场景中的服务与服务间的数据交互,其采用HTTP2(支持io多路复用)作为传输协议,使用protobuf作为序列化协议,并且支持多种开发语言。
4.2 对比一下HTTP1.0、HTTP1.1、HTTP2.0、HTTP3.0
HTTP/1.0:
- 连接方式(短连接):每个请求都需要建立一个新的TCP连接,完成之后立即关闭,这导致了较大的延迟。
- 基于文本的协议:传输文本格式的数据
- 单工:无法实现服务端的推送
HTTP1.1:
- 有限的长连接: 由keep-alived决定保持的时间,允许在一个TCP连接上发送多个请求和响应。
- 基于文本的协议:传输文本格式的数据
- 无法实现双工通信
- 存在队头阻塞的问题(不支持多路复用):下一个请求必须在前一个请求响应到达之后才能发送,假设前一个请求响应一直不到达,那么下一个请求就不发送,后面的请求就阻塞了。(一个连接上不能同时发出多个请求)
HTTP2.0:
- 长连接
- 多路复用:解决了HTTP/1.x中的队头阻塞问题,通过一条TCP连接可以同时进行多个请求和响应的传输。
- 二进制协议:传输二进制数据效率高
- 可以实现双工通信
- 仍存在可能因丢包重传阻塞所有流(TCP 层队头阻塞)
HTTP/3.0:
- 底层协议变更:最大的变化是从基于TCP变为基于UDP的QUIC协议,旨在减少连接建立时间并提高安全性。
- 快速握手:利用TLS 1.3实现了更快的安全握手过程,使得连接建立速度显著加快。
5.性能相关
5.1 性能数据是怎么得到的?
通过读取/proc文件系统下的相关文件得到。
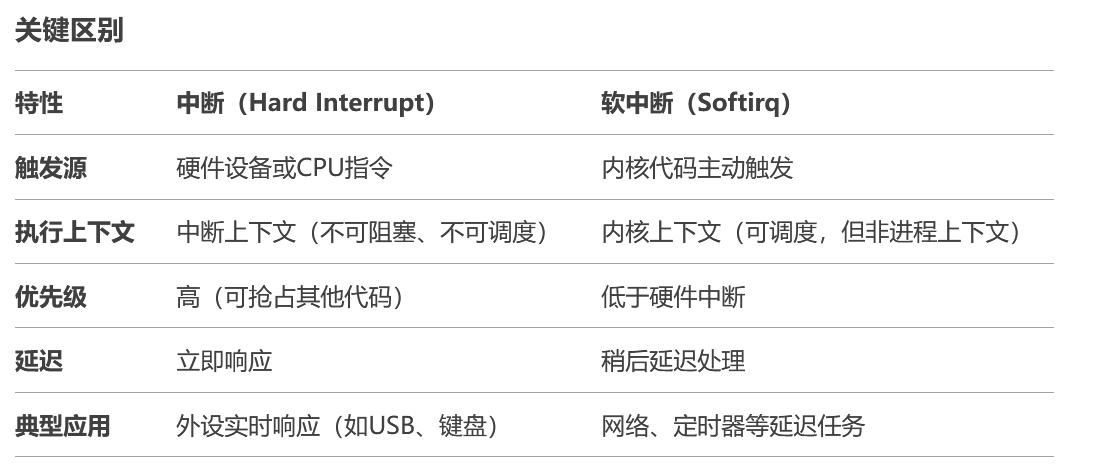
5.2 什么是中断?什么是软中断?
/proc/softirqs
中断:是一种异步的事件处理机制,可以提高系统的并发处理能力。
软中断(异常):
为了解决中断处理程序执行过长和中断丢失的问题,Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部(软中断)。
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
5.3 统计了内存相关的哪些信息?
/proc/meminfo 当前内存使用的统计信息,常由free命令使用
基础内存统计:
total: 系统的总物理内存大小free: 当前未被使用的物理内存大小。avail: 可用于启动新应用程序而无需交换的内存大小。它包括了空闲内存 (free) 和可回收的缓存(如文件缓存和部分 slab 缓存)。
缓存与缓冲区:
buffers: 块设备 I/O 操作的缓冲区内存大小。cached: 表示文件系统缓存占用的内存大小。……
活跃与非活跃内存
active: 最近被频繁访问的内存页面大小。这些页面不太可能被回收。in_active: 最近较少被访问的内存页面大小。这些页面可能被回收以释放内存。……
脏页与写回
dirty: 尚未写入磁盘的脏页(修改过的页面)的内存大小。这些页面需要尽快写回磁盘以确保数据一致性。writeback: 表示正在写回磁盘的页面的内存大小。这些页面已经被标记为“正在写入”,但尚未完成。
匿名内存
anon_pages: 表示匿名内存的总大小。匿名内存是指没有文件支持的内存区域,如堆、栈和通过mmap创建的匿名映射。……
可回收内存
kReclaimable: 表示内核中可回收的内存大小。这部分内存由内核管理,但可以被回收以供其他用途。……
6.Muduo库
6.1 介绍一下Muduo库的Reactor模型
Reactor模型其核心思想是“事件驱动”,即通过一个事件循环(EventLoop)监听多种事件,然后通过一个事件分发器分发给对应的事件处理器(回调函数)进行处理。
然而,在高并发的场景下,单线程的EventLoop可能无法满足性能需求。这是通常采用主Reactor线程和子Reactor线程的分离设计。
- 主Reactor线程:运行一个 EventLoop,负责监听服务器端口并接受新连接,并把连接分配给子Reactor线程。
- 子Reactor线程:每个线程都运行一个独立的 EventLoop,负责处理具体的 TCP 连接,后续的所有 IO 操作(如读写)都在对应的子线程中完成。
6.2 同步和异步的区别
同步:指任务依次执行,一个任务完成之后下一个任务才开始
异步:指任务可以不按顺序执行,发起一个任务后无需等待其完成即可继续执行其他任务,通过回调、通知或轮询等方式获取任务结果。
6.3 什么是事件驱动?Reactor模型是怎么实现事件驱动的?
事件驱动的核心思想是:
异步非阻塞:程序不会主动轮询或等待某个事件的发生,而是通过注册回调函数的方式,由底层框架在事件发生时通知应用程序。
事件循环(Event Loop):一个持续运行的循环,用于监听事件并调用相应的回调函数。
Reactor 模型的事件驱动流程
注册事件:将感兴趣的事件(如可读、可写、连接关闭等)注册到 Reactor 中。
setConnectionCallback注册了连接事件的回调函数OnConnectionsetMessageCallback注册了消息事件的回调函数OnMessage
监听事件:
loop.loop()启动事件循环,通过epoll监听服务器端口上的连接请求和已连接套接字上的读写事件。分发事件:
- 当有新连接到达时,Muduo 调用
OnConnection处理连接事件。 - 当有数据到达时,Muduo 调用
OnMessage处理消息事件。
- 当有新连接到达时,Muduo 调用
执行回调:
OnConnection和OnMessage执行具体的业务逻辑,例如打印日志、回显消息等。
7.Zookeeper
7.1 什么是Zookeeper?为什么使用Zookeeper?
Zookeeper是一个分布式协调工具,而在本项目中主要用到了它的服务注册与发现的功能。
具体的设计:
- 对于服务的提供者,以自己提供的服务名和方法作为Znode的路径,而将ip和端口作为Znode节点的数据,注册到zookeeper上。
- 对于服务的调用者,根据所请求的服务名和方法名就可以查找到对应服务器的ip和端口。
好处:
- 服务的调用者无需手动配置服务器的地址,只需提供服务名和方法名即可。
- Zookeeper提供了Watcher机制可以实时感知服务的上线和下线。
7.2 ZooKeeper 的 Watcher 机制是如何实现的?
Zookeeper 的观察者(Watcher)机制是一种事件通知机制,允许客户端在 ZNode 上设置观察者,以便在 ZNode 的数据或状态发生变化时接收通知。但在本项目中只使用了一个全局的global_watcher来监听客户端与服务器之间的连接状态变化
7.3 ZooKeeper客户端和服务器是长连接吗?
可以保持长连接,线程会定期向 ZooKeeper 服务器发送心跳包(Ping 消息),以确保连接的有效性。通过设置一个超时时间,如果客户端未收到服务器的响应(包括心跳响应),ZooKeeper 客户端会认为会话已过期,连接会被关闭。





